The v3 full rewrite failed, obviously. The project was simply too ambitious for the limited capacity of an open-source weekend project.
Rubberduck is at a crossroads: either there’s a way forward, or sooner or later it’s a way to the graveyard.
You thought this was going to be about Rubberduck going “on indefinite pause”, didn’t you? If you haven’t seen the recent movement around the project’s website and GitHub organization, I wouldn’t blame you for thinking so, but…
I can’t let that happen to Rubberduck. This project means too much to me, to just let it die like this.
Not after all the blood, guts, and sweat that went into it.
It’s 2026. VBA has been “dead” for what, 20 years now? It’ll be “dead” for another 15 and Microsoft will still do nothing about modernizing VBA: they’ve essentially left that ground to the community – and that’s us.
And I’m perfectly fine with that.
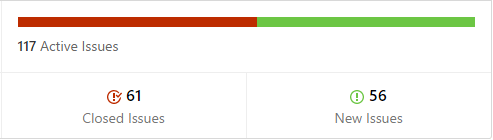
I have no idea how big or small Rubberduck’s user base is; all I have is rough estimates. I know the total number of installer downloads for any given release tag, that’s all. I never collected any data from our users, because an OSS project that can’t sign their code shouldn’t be doing that, plus where’s the infra and who’s paying for it? I’ve poured quite a lot of my own money into this over the course of the past decade or so, and Enterprise-approvable, certified/signed code is crazy expensive and simply wasn’t going to happen under a pure open-source GPLv3 model at my sole expense.
Meanwhile we’ve built a reputation for ourselves and are now positioned as the reference for professional-level VBA code, and Microsoft’s own flagship AI tool – Copilot – spontaneously names Rubberduck as the best tool in the ecosystem in 2026 and validates our unit testing features as a unit testing framework that is comparable to industry-standard NUnit/JUnit. To me it says something about how deep the actual reach goes, and how dead VBA actually still isn’t.

The mission is accomplished.
Are we done beating around the bush now?
Yes: I’m going all in.
Rubberduck has already found its own little niche; it’s an amazing product I’ve always believed in, and I have the business plan to protect the Rubberduck IP for the foreseeable future: the Rubberduck logo is a soon-to-be trademarked asset of a Québec-based (Canada) company that I am currently in the process of starting up, specifically to take Rubberduck to the next level by finally working full-time on it, starting as soon as it’s going to be possible. Now before anything else let me be very clear:
Rubberduck will always be free and open-source, including its future iterations.
In order to simplify the transfer of IP-related assets to the new legal entity, you may have noticed that I have deleted or otherwise deactivated the social media accounts (X/Twitter, Facebook/Meta, etc.), along with the Ko-fi and PayPal accounts. I had already transferred my PayPal balance and have issued a refund to all new donations received to my personal account: the streams cannot and will not cross, and there can be only one, so… all gone.
This blog will be archived. Being a Québec-Inc. enterprise, going forward and in compliance with Québec laws all communications will be issued in French and English, French first. DNS registration for rubberduckvba.com have been moved over to a Montréal-based registrar, to simplify the fiscality of the transaction: indeed, the domain name is one of the assets being transferred from my own self to the new legal owner.
Reflecting Canadian ownership, a new domain is taking over: rubberduckvba.ca will now be served instead of the historical .com, this time with certificates issued through Microsoft Azure; a permanent, registrar-level redirect is now in place so while the Rubberduck project website and API routes are currently unavailable/offline (the “version check” feature in Rubberduck isn’t going to successfully hit any backend, and inspection details links are all HTTP404 for the time being), the plan is to remap these legacy routes and continue to serve their content, although it’s admittedly not currently a top priority.
The GitHub repositories have been archived. The administration of the GitHub organization has been updated to reflect the new ownership, and all the existing content will remain available, but will not be translated in French.
It’s the end of this blog then?
Depends how you see it, really. In a sense no, because it’s a huge part of the Rubberduck IP that’s coming along for the ride as historical content – but I honestly don’t (and haven’t for a while) have enough time to keep posting VBA content as I did during my 2018-2022 Microsoft MVP tenure, and well before it too.
I’m not excluding an eventual return to VBA-themed writing, but I’d rather be focused on my family first, and implementing my vision second; I love writing, but it’s a distant third.
So… What’s next?
I can’t yet disclose what’s next, actually. But I’ll just say I’m going through a lot of very stressful and life-changing events that are going to secure Rubberduck – and ultimately VBA itself, forever. Mark my words:
This company will make VBA immortal.
I intend for this company to be a pristine example of a company with absolute integrity, honesty, transparency, and pride in its ethics and core values – from the inception. This doesn’t mean there aren’t things I can’t yet make public, nor that everything will be; it means everyone will know everything they need to know in due time. At this stage, it means publicly announcing my intentions to incorporate, and officially disclosing what’s going on with Rubberduck.
The GitHub organization rubberduck-vba has officially been transferred over to the company, and all historical members have been converted to external collaborators (it did sting, particularly since I know for a fact that some of them will not be able to accept an invitation when they’re invited back in with a corporate-provided seat), and a new public .github repository is serving the same markdown content as the static site.
Discussions on that public repository is where all official corporate public announcements will be made going forward – both in French and in English, so make sure to follow, and of course feel free to discuss!
- Announcement: Prise en charge corporative | Corporate stewardship
- Want to help? The Rubberduck and Me form aims to help me / the company get a better understanding of the Rubberduck user base as an aggregate.