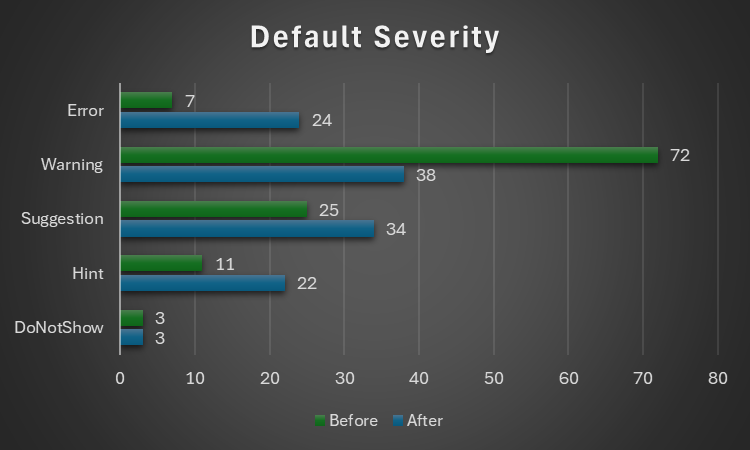
Longue vie au concombre
Le 26 mai 2026 marquera le 10e anniversaire de la découverte par le contributeur historique @Comintern de ce message cryptique à la clé de resource 18089 de la librairie VBE7INTL.DLL:
STRINGTABLE
LANGUAGE LANG_ENGLISH, SUBLANG_ENGLISH_US
{
18080, "Tile Horizontally"
18081, "Tile Vertically"
18082, "Arrange Icons"
18083, "Microsoft Visual Basic for Applications Help Topics"
18084, "Search Reference Index..."
18085, "Obtaining Technical Support"
18088, "About Microsoft Visual Basic for Applications..."
18089, "Long Live the Cucumber"
18090, "Break On All"
18091, "Break In Ole Server"
18092, "Break On Unhandled"
}
Le projet Rubberduck a toujours voulu s’approprier cette phrase et s’en servir quelque part d’une façon ou d’une autre.
Rubberduck Core marine ce concombre depuis un certain temps, et fait de cette phrase son slogan, en latin:

Il y a plusieurs niveaux à cette imagerie: plongeons.
Gravé dans la pierre
Quand on dit de quelque chose qu’il est gravé dans la pierre, on décrit quelque chose d’immuable, ou qui n’est pas prêt de changer. Un peu comme les spécifications d’un certain langage de programmation.
La pierre taillée évoque l’antiquité et la renaissance, mais aussi les pierres tombales et les cimetières, où l’on pourrait s’attendre à retrouver une langue morte comme le latin… ou VBA. Ça dit “ceci existe depuis longtemps”, mais aussi “ceci fait partie de notre héritage”.
La pierre est une fondation solide, noble. Elle est aussi lourde, et peut être un fardeau tout comme le code hérité – ou pour Microsoft tout comme le support des librairies d’exécution de VBA. Elle dit malgré tout “ceci existera encore longtemps”.
VBA est mort, vive VBA!
Peut-être que le proverbial concombre se voulait réellement référer à Visual Basic même, mais c’est sans importance de toute façon parce que VBA a effectivement survécu, et donc le soulier fait, même si c’est a posteriori.
L’utilisation d’une image qui pourrait être interprétée comme une pierre tombale pour quelque chose qui est lié à VBA assume complètement la nature “intuable” du langage et la profonde ironie de le voir survivre à chaque produit ou technologie qui tente désespérément et successivement de le remplacer : VBA est mort, longue vie à VBA!
Modernisation
Rubberduck Core conserve les racines et fait évoluer le concept, alors on passera éventuellement de la pierre au métal – à l’acier :

L’acier est toujours la pierre, en quelque sorte. Cuisinée un peu certes (bon d’accord, carrément séparée du métal…), mais néanmoins il vient de la pierre. Brute, lourde et difficile à manier, maintenant raffinée, élégante et polie, relativement légère mais robuste et durable. Et brillante aussi. L’âme y est clairement toujours.
C’est précisément ce qui va se produire avec Rubberduck : le concombre ne fait que mariner encore un peu… parce qu’une décennie plus tard, celui-là n’est toujours pas un cornichon.
rubberduckvba.ca
Le site historique du projet rubberduckvba.com redirige désormais vers rubberduckvba.ca et le dépôt du projet Rubberduck sur GitHub est maintenant archivé en lecture seule. Les efforts de développement pour la prochaine évolution sont en cours dans un dépôt pour l’instant privé sous la même organisation rubberduck-vba; Rubberduck Core en sera bientôt le nouveau projet-phare en mode Open-Core, soutenu par 9562-7303 Québec inc., une société privée fondée à cet effet par le même auteur principal de Rubberduck et auteur de ce blogue depuis son commencement.
Être incorporé au Québec signifie que toutes les communications officielles seront publiées dans ce format en français d’abord, avec un lien immédiat vers le contenu équivalent en anglais. Ça signifie également que la disponibilité du contenu dans une langue autre que l’anglais n’est pas un ajout, mais une nécessité : tout comme Rubberduck, Rubberduck Core (ou RDCore pour faire plus court) sera assurément disponible en français et en anglais dès le jour un, et ensuite dans toutes les langues que la communauté rendra disponibles. Ce n’est pas un fardeau, mais une opportunité. Vos documents seront toujours envoyés dans la langue de votre choix.
(C) 2026 Mathieu Guindon pour 9562-7303 Québec inc.
English
Long Live the Cucumber
May 26, 2026 will mark the 10th anniversary of the discovery by core historical contributor @Comintern of this cryptic message at resource key 18089 of the VBE7INTL.DLL library:
STRINGTABLE
LANGUAGE LANG_ENGLISH, SUBLANG_ENGLISH_US
{
18080, "Tile Horizontally"
18081, "Tile Vertically"
18082, "Arrange Icons"
18083, "Microsoft Visual Basic for Applications Help Topics"
18084, "Search Reference Index..."
18085, "Obtaining Technical Support"
18088, "About Microsoft Visual Basic for Applications..."
18089, "Long Live the Cucumber"
18090, "Break On All"
18091, "Break In Ole Server"
18092, "Break On Unhandled"
}
The Rubberduck project always wanted to appropriate this phrase and use it somewhere, somehow.
Rubberduck Core marinates the cucumber and makes the quote its catchphrase, coined in Latin:
There are a few layers to this imagery: let’s dive.
Carved in Stone
When we say something is carved in stone, we are describing something that is either immutable, or isn’t about to change – much like the specifications of a certain programming language.
Carved stone evokes Antiquity and Renaissance, but also cemeteries and headstones, like where you would expect to find a dead language like Latin… or VBA. It says “this has been around for a long time”, and also “this is part of our heritage”
Stone is rock solid, foundational, noble. It’s also heavy, and it can be a burden, like legacy code – or if we ask Microsoft, like runtime support for VBA. It nevertheless still says “this will be around for a long time”.
VBA is Dead, Long Live VBA!
Maybe “the cucumber” really did refer to Visual Basic itself, but it wouldn’t matter if it didn’t: VBA lived on, so the shoe fits even if a posteriori.
Using something that can be construed as a headstone to depict something related to VBA leans heavily onto its “unkillable” nature and the profound irony of it surviving every single one of its successive replacement attempts: VBA is dead, long live VBA!
Modernization
Rubberduck Core keeps the roots and evolves the concept, and so we will eventually grow out of stone, to metal – to steel:
Steel is still the stone, in a way – crushed and cooked (narrator: fully separated from it, actually), but it came from the stone. Crude, heavy and unwieldy, it ultimately becomes refined, elegant and polished, relatively lightweight but extremely solid and reliable. And shiny. The soul is still there.
That’s exactly what’s going to happen with Rubberduck – the cucumber is only marinating a little longer… because a decade later, this one still hasn’t pickled yet.
rubberduckvba.ca
The historical project site rubberduckvba.com is now redirecting to rubberduckvba.ca and the Rubberduck repository on GitHub is now archived/read-only. Development efforts towards the next evolution are currently in progress in a private repository under the same rubberduck-vba organization; Rubberduck Core will soon be its flagship Open-Core project under 9562-7303 Québec inc., a private company founded for this specific purpose by the same primary author of Rubberduck and of this blog since its inception.
Being incorporated in Québec means all public communications are going to be issued in a French-first format, with an immediate link to the English content. It also means that localization isn’t an afterthought in this company, but a necessity: like Rubberduck before it, Rubberduck Core (or RDCore for short) shall be assuredly available in both French and English, and then every language it would end up being translated into. It’s not a burden, but an opportunity. Your documents will always be emailed in the language of your choosing.
(C) 2026 Mathieu Guindon on behalf of 9562-7303 Québec inc.