At least according to our issues list.
I’ve been working on quite a lot of things these past few weeks, things that open up new horizons and help stabilize the foundations – the identifier reference resolver.
Precompiler Directives
And we’ve had major contributions too, from @autoboosh: Rubberduck’s parser now literally interprets precompiler directives, which leaves only the “live” code path for the parsing and resolving to work with. This means you can scratch what I wrote in an earlier post about this snippet:
[…] Not only that, but a limitation of the grammar makes it so that whatever we do, we’ll never be able to parse the [horrible, awfully evil] below code correctly, because that #If block is interfering with another parser rule:
Private Type MyType
#If DEBUG_ Then
MyMember As Long
#Else
MyMember As Integer
#End If
End Type
And this (thoroughly evil) one too:
#If DEBUG_ Then
Sub DoSomething()
#Else
Sub DoSomethingElse()
#End If
'...
End Sub
Rubberduck 2.0 will have no problem with those… as long as DEBUG_ is defined with a #Const statement – the only thing that’s breaking it is project-wide precompiler constants, which don’t seem to be accessible anywhere from the VBIDE API. Future versions might try to hook up the project properties window and read these constants from there though.
Isn’t that great news?
But wait, there’s more.
Project References
One of the requirements for our resolver to correctly identify which declaration an identifier might be referring to, is to know what the declarations are. Take this code:
Dim conn As New ADODB.Connection
conn.ConnectionString = "..."
conn.Open
Until I merged my work last night, the declarations for “ADODB” and “Connection” were literally hard-coded. If your code was referencing, say, the Scripting Runtime library to use a Dictionary object, the resolver had no way of knowing about it, and simply ignored it. The amount of work involved to hard-code all declarations for the “most common” referenced libraries was ridiculously daunting and error-prone. And if you were referencing a less common library, it was “just too bad”. Oh, and we only had (parts of) the Microsoft Excel object model in there; if you were working in Access or Word, or AutoCAD, or any other host application that exposes an object model, the resolver simply treated all references to these types and their members, as undeclared identifiers – i.e. they were completely ignored.
I deleted these hard-coded declarations. Every single one of them. Oh and it felt great!
Instead, Rubberduck will now load the referenced type libraries, and perform some black magic COM reflection to discover all the types and their members, and create a Declaration object for the resolver to work with.
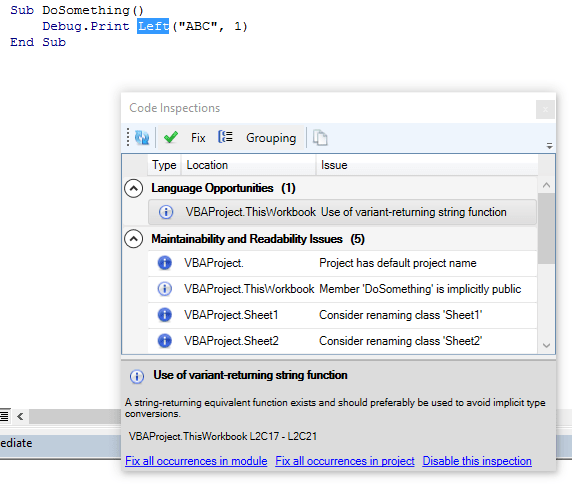
This enables things like code inspections specific to a given type library, that only run when that library is referenced:
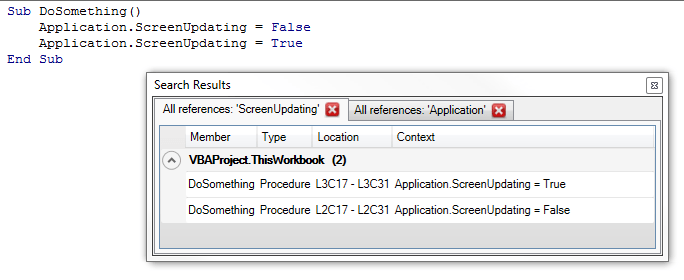
It also enables locating and browsing through references of not only your code, but also built-in declarations:
Doing this highlighted a major performance issue with the resolver: all of a sudden, there was 50,000 declarations to iterate whenever we were looking for an identifier – and the resolver did an awful job at being efficient there. So I changed that, and now most identifier lookups are O(1), which means the resolver now completes in a fraction of the time it took before.
There’s still lots of room for improvement with the resolver. I started to put it under test – the unit tests for it are surprisingly easy to write, so there’s no excuse anymore; with that done, we’ll know we’re not breaking anything when we start refactoring it.
One of the limitations of v1.x was that project references were being ignored. Well, the resolver is now equipped to start dealing with those – that’s definitely the next step here.
Module/Member Attributes
Another limitation of v1.x was that we couldn’t see module attributes, so if a class had a PredeclaredId, we had no way of knowing – so the resolver essentially treated classes and standard modules the same, to avoid problems.
Well, not anymore. The first time we process a VBComponent, we’re silently exporting it to a temporary file, and give the text file to a specialized parser that’s responsible for picking up module and member attributes – then we give these attributes to our “declarations” tree walker, which creates the declaration objects. As a result, we now know that a UserForm module has a PredeclaredId. And if you have a VB_Description attribute for each member, we pick it up – the Code Explorer will even be able to display it as a tooltip!
What about multithreading?
I tried hard. Very hard. I have a commit history to prove it. Perhaps I didn’t try hard enough though. But the parser state simply isn’t thread-safe, and with all the different components listening for parser state events (e.g. StateChanged, which triggers the code inspections to run in the background and the code and todo explorers to refresh), I wasn’t able to get the parser to run a thread-per-module and work in a reliable way.
Add to that, that we intend to make async parsing be triggered by a keyhook that detects keypresses in a code pane, parsing on multiple threads and getting all threads to agree on the current parser state is a notch above what I can achieve all by myself.
So unless a contributor wants to step in and fix this, Rubberduck 2.0 will still be processing the modules sequentially – the difference with 1.x is the tremendous resolver performance improvements, and the fact that we’re no longer blocking the UI thread, so you can continue to browse (and modify!) the code while Rubberduck is working.
What’s left to do for this to work well, now that the parsing and resolving is stabilized, is to allow graceful cancellation of the async task – because if you modify code that’s being parsed or resolved, the parser state is stale before the task even completes.
To be continued…
(hint: IDE-integrated source control)





