The release was going to include a number of important fixes for the missing annotation/attribute inspection and quick-fix, but instead we disabled it, along with a few other buggy inspections, and pushed the release – 7 months after 2.0.13, the last release was now over 1,300 commits behind, and we were reaching a point where we knew a “green release” was imminent, but also a point where we were going to have to make some more changes to parts of the core – notably in order to implement the fixes for these broken annotation/attribute inspections.
So we shipped what we had, because we wouldn’t jeopardize the 2.1 release with parser logic changes at that point.
Crossroads
By Hillebrand Steve, U.S. Fish and Wildlife Service [Public domain], via Wikimedia CommonsSo here we are, at the crossroads: with v2.1.0 released, things are going to snowball – there’s a lot on our plates, but we now have a solid base to build upon. Here’s what’s coming:
Castle Windsor IoC: hopefully-zero user-facing changes, we’re replacing good old Ninject with a new dependency injection framework in order to gain finer control over object destruction – we will end up correctly unloading!
That’s actually priority one: the port is currently under review on GitHub, and pays a fair amount of long-standing technical debt, especially with everything involving menus.
Annotation/Attributes: fixing these inspection, and the quick-fix that synchronizes annotations with module attributes and vice-versa, will finally expose VB module and member attributes to VBA code panes, using Rubberduck’s annotation syntax.
For example, adding '@Description("This procedure does XYZ") on top of a procedure will tell Rubberduck that you mean that procedure to have a VB_Description attribute; when Rubberduck parses that module after you synchronize, it will be able to use that description in the context status bar, or as tooltips in the Code Explorer.
IgnoreOnce: this quick-fix is supported by pretty much every single inspection, and means to insert an ‘@Ignore SomeInspectionNameannotation, but the current implementation has a bug that makes successive calls offset the insertion line, which obviously results in broken code.
This is considered a serious issue, because it affects pretty much every single inspection. Luckily there’s a [rather annoying and not exactly acceptable] work-around (apply the fix bottom-to-top in a module), but still.
But there’s a Greater Picture, too.
The 2.1.x Cycle
At the end of this development cycle, Rubberduck will:
Work in the VB6 IDE;
Have formalized the notion of an experimental feature;
Have a working Extract Method refactoring;
Make you never want to use the VBE’s Project References dialog ever again;
Compute and report various code metrics, including cyclomatic complexity and nesting levels, and others(and yes, line count too);
Maybe analyze a number of execution paths and implement some of the coolest code inspections we could think of;
Be ready to get really, really serious about a tear-tab AvalonEdit code pane.
If all you’re seeing is Rubberduck’s version check, the next version you’ll be notified about will be 2.1.2, for which we’re shooting for 2017-11-13. If you want to try every build until then (or just a few), then you’ll want to keep an eye on our releases page!
Last time I went over the startup and initialization of Rubberduck, and I said I was going to follow it up with how the parser and resolver work.
Just so happens that Max Dörner, who has pretty much owned the parser and resolver parts of Rubberduck since he joined the project (that’s right – jumped head-first into some of the toughest, most complicated code in the project!), has nicely documented the highlights of how parsing and resolving works.
So yeah, all I did here was type up an intro. Buckle up, you’re in for a ride!
Part 2: Parsing & Resolving
Rubberduck processes the code in all unprotected modules in a five-step process. First, in the parser state Pending, the projects and modules to parse are determined. Then, in the parser state LoadingReferences, the references currently used by the projects, e.g. the Excel object model, and some built-in declarations are loaded into Rubberduck. Following this, the actual processing of the code begins. Between the parser states Parsing and Parsed the code gets parsed into parse trees with the help of Antlr4. Following this, between the states ResolvingDeclarations and ResolvedDeclarations the module, method and variable declarations are generated based on the parse tree. Finally, between the states ResolvingReferences and Ready the parse trees are walked a second time to determine the references to the declarations within the code.
At each state change, an event is fired which can be handled by any feature subscribing to it, e.g. the CodeExplorer, which listens for the state change to ResolvedDeclarations.
A More Detailed Story
The entry point for the parsing process is the ParseCoordinator inside the Rubberduck.Parsingassembly. It coordinates the parsing process and is responsible for triggering the appropriate state changes at the right time, for which it uses a IParserStateManager passed to it. To trigger the different stages of the parsing process, the ParseCoordinator uses a IParsingStageService. This is a facade passed to it providing a unified interface for calling the individual stages, which are all implemented in an individual set of classes. Each has a concurrent version for production and a synchronous one for testing. The latter was needed because of concurrency problems of the mocking framework.
General Logistics
Every parsing run gets executed in fresh background task. Moreover, to always be in a consistent state, we allow only one parsing run to execute at a time. This is achieved by acquiring a lock in a top level method. This top level method is also the point at which any cancellation or unexpected exception will be caught and logged.
The first step of the actual parsing process is to set the overall parser state to Pending. This signals to all components of Rubberduck that we left a fully usable state. Afterwards, we refresh the projects cache on the RubberduckParserState asking the VBE for the loaded projects and then acquire a collection of the modules currenlty present.
Loading References
After setting the overall parser state to LoadingReferences, the declarations for the project references, i.e. the references selected in Tools –> References... , get loaded into Rubberduck. This is done using the ReferencedDeclarationsCollector in the Rubberduck.Parsing.ComReflectionnamespace, which reads the appropriate type libraries and generates the corresponding declarations.
Note that the order in the References dialog determines what procedure or field an identifier resolves to in VBA if two or more references define a procedure or field of the same name. This prioritization is taken into account when loading the references.
Unfortunately, we are currently not able to load all built-in declarations from the type libraries: there are some hidden members of the MSForms library, some special syntax declarations like LBound and everything related to Debug, and aliases for built-in functions like Left, where Leftis the alias for the actual hidden function defined in the VBA type library. These get loaded as a set of hand-crafted declarations defined in the Rubberduck.Parsing.Symbols.DeclarationLoadersnamespace.
Parsing the Code
At the start of the processing of the actual code, the parser state is set to Parsing. However, this time this is achieved by setting the individual modules states of the modules to be parsed and then evaluating the overall state.
Each module gets parsed separately using an individual ComponentParseTask from the Rubberduck.Parsing.VBA namespace, which is powered by the Antlr4 parser generator. The end result is a pair of two parse trees providing a structured representation of the code one time as seen in the VBE and one time as exported to file.
The general process using Antlr is to provide the code to a lexer that turns the code into a stream of tokens based on lexer rules. (The lexer rules used in Rubberduck can be found in the file VBALexer.g4 in the Rubberduck.Parsing.Grammar namespace.) Then this token stream gets processed by a parser that generates a parse tree based on the stream and a set of parser rules describing the syntactic rules of the language. (The VBA parser rules used in Rubberduck can be found in the file VBAParser.g4 in the Rubberduck.Parsing.Grammar namespace. However, there are more specialized rules in the project). The parse tree then consists of nodes of various types corresponding to the rules in the parser rules.
Even when counting the Antlr workflow described above as one step, the actual parsing process in the ComponentParseTask is a multi stage process in itself. This has two reasons: there are precompiler directives in VBA and some information regarding modules is hidden from the user inside the VBE, namely attributes.
The precompiler directives in VBA allow to conditionally select which code is alive. This allows to write code that would only be legal VBA after evaluating the conditional compilation directives. Accordingly, this has to be done before the code reaches the parser. To achieve this, we parse each module first with a specialized grammar for the precompiler directives and then hide all tokens that are dead after the evaluation from the VBA parser, including the precompiler directives themselves, by sending the tokens to a hidden channel in the tokenstream. Afterwards, the dead code is still part of the text representation of the tokenstream by disregarded by the parser.
To cover both the attributes, which are only present in the exported modules, and provide meaningful line numbers in inspection results, errors and the command bar, we parse both the attributes and the code as seen in the VBE code pane into a separate parse tree and save both on the ModuleState belonging to the module on the RubberduckParserState.
One thing of note is that Antlr provides two different kinds of parsers: the LL parser that basically parses all valid input for every not indirectly left-recursive grammar (our VBA grammar satisfies this) and the SLL parser, which is considerably faster but cannot necessarily parse all valid input for all such grammars. Both parsers are guaranteed to yield the same result whenever the parse succeeds at all. Since the SLL parser works for next to all commonly encountered code, we first parse using it and fall back to the LL parser if there is a parser error.
Following the parse, the state of the module is set to Parsed on a successful parse and to ParserError, otherwise. After all modules have finished parsing, the overall parser state is evaluated. If there has been any parser error, the parsing process ends here.
Resolving Declarations
After parsing the code into parse trees, it is time to generate the declarations for the procedures, functions, properties, variables and arguments in the code.
First, the state of all modules gets set to ResolvingDeclarations, analogous to the start of parsing the code. Then the tree walker and listener infrastructure of Antlr is used to traverse the parse trees and generate declarations whenever the appropriate grammar constructs are encountered. This is done inside the implementations of IDeclarationResolveRunner in the Rubberduck.Parsing.VBAnamespace.
Note that there is still some information missing on the declarations at this point that cannot be determined in this first pass over the parse trees. E.g. the supertypes of classes implementing the interface of another class are not known yet and, although the name of the type of each declaration is already known, the actual type might not be known yet. For both cases we first have to know all declarations.
After the parse trees of all modules have been walked, the overall parser state gets set to ResolvedDeclarations, unless there has been an error, which would result in the state ResolverError and an immediate stop of the parsing run.
Resolving References
After all declarations are known, it is possible to resolve all references to these declarations within the code, beit as types, supertypes or in expressions. This is done using the implementations of IReferenceResolveRunner in the Rubberduck.Parsing.VBA namespace.
First, the state of the modules for which to resolve the references gets set to ResolvingReferencesand the overall state gets evaluated. Then the CompilationPasses run. In these the type names found when resolving the declarations get resolved to the actual types. Moreover, the type hierarchy gets determined, i.e. super- and and subtypes get added to the declarations based on the implements statements in the code.
After that, the parse trees get walked again to find all references to the declarations. This is a slightly complicated process because of the various language constructs in VBA. As a side effect, the variables not resolving to any declaration get collected. Based on these, new declarations get created, which get marked as undeclared. These form the basis for the inspection for undeclared variables.
After all references in a module got resolved, the module state gets set to Ready. If there is some error, the module state gets set to ResolverError. Finally, the overall state gets evaluated and the parsing run ends.
Handling State Changes
On each change of the overall state, an event is raised to which other features can subscribe. Examples are the CodeExplorer, which refreshes on the change to ResolvedDeclarations, and the inspections, which run on the change to Ready.
Handling any state change but the two above is discouraged, except maybe for the change to Pending or the error states if done to disable things. The problem with the other states is that they may never be encountered during a parsing run due to optimizations. Moreover, Rubberduck is generally not in a stable state between Pending and ResolvedDeclarations. Features requiring access to references should generally only handle the Ready state.
Events also get raised for changes of individual module states. However, it should be preferred to handle overall state changes because module states change a lot, especially in large projects.
IMPORTANT: Never request a parse from a state change handler! That will cancel the current parse right after the handlers for this state in favor of the newly requested one.
Doing Only What Is Necessary
When parsing again after a successful parsing run, the easiest way to proceed is to throw away all information you got from the last parsing run and start from scratch. However, this is quite wasteful since typically only a few modules change between parsing runs. So, we try to reuse as much information as possible from prior parsing runs. Since our VBA grammar is build for parsing entire modules the smallest unit of reuse of information we can work with is a module.
We only reparse modules that satisfy one of three conditions: they are new, modified, or not in the state Ready. For the first two conditions it should be obvious why we have to reparse such modules. The question is rather how we evaluate these conditions.
To be able to determine whether a module has changed, we save a hash of the code contained in the module whenever the module gets parsed successfully. At the start of the parsing run, we compare the saved hash with the hash of the corresponding freshly loaded component to find those modules with modified content. In addition we save a flag on the module telling us whether the content hash has ever been saved. If this is not the case, the module is regarded as new.
For the third condition the question is rather why we also reparse such modules. The reason is that such modules might be in an invalid state although the content hash had been written in the last parsing run. E.g. they might have encountered a resolver error or they got parsed successfully in the last parsing run, but the parsing run got cancelled before the declarations got resolved. In these cases the content hash has already been saved so that the module is neither considered to be new nor modified. Consequently, it would not be considered for parsing and resolving if only modules satisfying one of the first two conditions were considered. Because of the possibility of such problems, we rather err on the save side and reparse every module that has not reached the success state Ready.
Since reparsing makes all information we previously acquired about the module invalid, we have to resolve the declarations anew for the modules we reparse. Fortunately, the base characteristics of a declaration only depend on the module it is defined in. So, we only have to resolve declarations for those modules that get reparsed. For references the situation is more complicated.
Since all declarations from the modules we reparse get replaced with new ones, all references to them, all super- and subtypes involving the reparsed modules and all variable and method types involving the reparsed modules are invalid. So, we have to re-resolve the references for all modules that reference the reparsed modules. To allow us to know which modules these are we save the information which module references which other modules in an implementation of IModuleToModuleReferenceManager accessed in the ParseCoordinator via the IParsingCacheService facade. This information gets saved whenever the references for all modules have been resolved successfully, even before evaluating the overall parser state.
In addition to the modules that reference modules that got reparsed, we also re-resolve those modules that referenced modules or project references having just been removed. This is necessary because the references might now point to different declarations. In particular, a renamed module is treated as unrelated to the old one. This means that renaming a module looks to Rubberduck like the removal of the old module and the addition of a new module with a new name.
The final optimization in place on a reparse is that we do not reload the referenced type libraries or the special built-in declarations every time. We just reload those we have not loaded before.
Caching and Cache Invalidation
If you have read the previous paragraph, you might have already realized that the additional speed due to only doing what is necessary comes at a cost: various types of cached data get invalid after parsing and resolving only some modules. So we have to remove the data at a suitable place in the parsing process. To achieve this the ParseCoordinator primarily calls different methods from the IParsingCacheService facade handed to it.
In the next sections we will work our way up from cache data for which you would probably seldom realize that we forgot to remove it to data for which forgetting to remove it sends the parser down in flames. After that, we will finish with a few words about refreshing the DeclarationFinder on the RubberduckParserState.
Invalid Type Declarations
The kind of cache invalidation problem you would probably not realize is that the type as which a variable is defined has to be replaced in case it is a user defined class and the class module gets reparsed; it now has a different declaration. This would probably just cause some issues with some inspections because the actual IdentifierReference tying the identifier to the class declaration is not related to the type declaration we save. Fortunately, the TypeAnnotationPass works by replacing the type declaration anyway. So, we just have to do that for all modules for which we resolve references.
Invalid Super- and Subtypes
As mentioned in the section about resolving references, we run a TypeHierarchyPass to determine the super- and subtypes of each class module (and built-in library). After reparsing a module, we have to re-resolve its supertypes. However, we also have to remove the old declaration of the module itself from the supertypes of its subtypes and from the subtypes of its supertypes, which has some further data invalidation consequences. Otherwise, the “Find all Implementations” dialog or the rename refactoring might produce …interesting results for the affected modules.
The removal of the super- and subtypes is performed via an implementation of ISupertypeCleareron all modules we re-resolve, including the modules we reparse, before clearing the state of the modules to be reparsed. Here, a removal of the supertypes is sufficient because everything is wired up such that manipulating the supertypes automatically triggers the corresponding change on the subtypes.
Invalid Module-To-Module References
As with all other reference caches, part of our cache saving which module references which other modules can become invalid when we re-resolve a module; it might just be that the the part referencing another module is gone. Fortunately, the way these references are saved does not depend on the actual declarations. So reparsing alone does not cause problems. This allows us to defer the removal of the module-to-module references to the reference resolver.
Being able to postpone the removal until we resolve references is fortunate because of potential problems with cancellations. We use the module-to-module references to determine which modules need to be re-resolved. If they got removed and the parsing run got cancelled before they got filled again in the reference resolver, we would potentially miss modules we have to re-resolve. Then the user would need to modify the affected modules in order to force Rubberduck to re-resolve them.
To handle this problem, the reference resolver itself has a cache of the modules to resolve, which is only cleared at the very end of its work. This is safe because the reference resolver only ever processes modules for which it can find a parse tree on the RupperduckParserState.
Invalid References
Invalid IndentifierReferences to declarations from previous parsing runs can cause any number of strange behaviors. This can range from selections referring to references that have once been at that line and column but having been removed in the meantime to refactorings changing things they really should not change.
It is rather clear that the references from all modules to be re-resolved should be removed. However, this is not as straightforward as it seems. The problem is that the references live in a collection on the referenced declaration and not in a collection attached to the module whose code is referencing the declaration. In particular, this makes it easy to forget to remove references from built-in declarations. To avoid such issues, we extracted the logic for removing references by a module into implementations of IReferenceRemover, which is hidden behind the IParsingCacheService facade.
Modules And Projects That No Longer Exist
Now we come to the piece where everything falls to pieces if we are not doing our job, modules and projects that get removed from the VBE. The problem is that some functionality like the CodeExplorer has to query information from the components in the VBE via COM Interop. If a component does no longer exist when the information gets queried, the parsing run will die with a COMException and there is little we can do about that. So we have to be careful to remove all declarations for no longer existing components right at the start of the parsing run.
To find out which modules no longer exist, we simply collect all the modules on the declarations we have cached and compare these to the modules we get from the VBE. More precisely, we compare the identifiers we use for modules, the QualifiedModuleNames. This will also find modules that got renamed. Projects are bit more tricky since they are usually treated as equal if their ProjectIds are the same; we save these in the project help file. Thus, we have to take special care for renamed projects. Knowing the removed projects, their modules get added to the removed modules as well.
Removing the data for removed modules and projects is a bit more complicated than for modules that still exist. After their declarations got removed, there is no sign anymore that they ever existed. So, we have to take special care to remove everything in the right order to guarantee that all information is gone already when we erase the declaration; after each step, the parsing run might be cancelled.
The final effect of removing modules is that the modules referencing the removed modules need to be re-resolved. Intuitively one might think that this will always result in a resolver error. However, keep in mind that renaming is handled as removing a module and adding another. Then the references will simply point to the new renamed module. Because of possible cancellations on the way to resolving the references, we immediately set the state of the modules to be re-resolved to ResolvingReferences. This has the effect that they will be reparsed in case of a cancellation.
Note that basically the same procedure is also necessary whenever we reload project references. Accordingly, we do this right after unloading the references, without allowing cancellations in between.
Refreshing the DeclarationFinder
Since declarations and references change in nearly all steps of the parsing process, we have to refresh our primary cached source of declarations, the DeclarationFinder, quite regularly when parsing. Unfortunately, this is a rather computation intensive thing to do; a lot of dictionaries get populated. So, we refresh only if we need to. E.g. we do not refresh after loading and unloading project references in case nothing changed. However, there are two points in each parsing run where we always have to refresh it: before setting the state to ResolvedDeclarations and before evaluating the overall state at the end of the parsing run, which results in the Ready state in the success path.
Refreshing before the change to ResolvedDeclarations is necessary to ensure that removed modules vanish from the DeclarationFinder before the handlers of this state change event run, including the CodeExplorer. We have to refresh again at the end because, from inside the ParseCoordinator, we can never be sure that the reference resolver did not do anything; it has its own cache of modules that need to be resolved.
One optimization done in the DeclarationFinder itself is that some collections are populated lazily, in particular those dealing only with built-in declarations. This saves the time to rebuild the collections multiple times on each parsing run. However, there is a price to pay. The primary users of the DeclarationFinder are the reference resolver and the inspections, both of which are parallelized. Accordingly, it can happen that multiple threads race to populate the collections. This is bad for the performance of the corresponding features. So, we make compromises by immediately populating the most commonly used collections.
Recently I asked on Twitter what the next RD News post should be about.
Seems you want to hear about upcoming new features, so… here it goes!
The current build contains a number of breakthrough features; I mentioned an actual Fakes framework for Rubberduck unit tests in an earlier post. That will be an ongoing project on its own though; as of this writing the following are implemented:
Fakes
CurDir
DoEvents
Environ
InputBox
MsgBox
Shell
Timer
Stubs
Beep
ChDir
ChDrive
Kill
MkDir
RmDir
SendKey
As you can see there’s still a lot to add to this list, but we’re not going to wait until it’s complete to release it. So far everything we’re hijackinghooking up is located in VBA7.DLL, but ideally we’ll eventually have fakes/stubs for the scripting runtime (FileSystemObject), ADODB (database access), and perhaps even host applications’ own libraries (stabbingstubbing the Excel object has been a dream of mine) – they’ll probably become available as separate plug-in downloads, as Rubberduck is heading towards a plug-in architecture.
The essential difference between a Fake and a Stub is that a Fake‘s return value can be configured, whereas a Stub doesn’t return a value. As far as the calling VBA code is concerned, that’s nothing to care about though: it’s just another member call:
[ComVisible(true)]
[Guid(RubberduckGuid.IStubGuid)]
[EditorBrowsable(EditorBrowsableState.Always)]
public interface IStub
{
[DispId(1)]
[Description("Gets an interface for verifying invocations performed during the test.")]
IVerify Verify { get; }
[DispId(2)]
[Description("Configures the stub such as an invocation assigns the specified value to the specified ByRef argument.")]
void AssignsByRef(string Parameter, object Value);
[DispId(3)]
[Description("Configures the stub such as an invocation raises the specified run-time eror.")]
void RaisesError(int Number = 0, string Description = "");
[DispId(4)]
[Description("Gets/sets a value that determines whether execution is handled by Rubberduck.")]
bool PassThrough { get; set; }
}
So how does this sorcery work? Presently, quite rigidly:
Not an ideal solution – the IFakesProvider API needs to change every time a new IFake or IStub implementation needs to be exposed. We’ll think of a better way (ideas welcome)…
So we use the awesomeness of EasyHook to inject a callback that executes whenever the stubbed method gets invoked in the hooked library. Implementing a stub/fake is pretty straightforward… as long as we know which internal function we’re dealing with – for example this is the Beep implementation:
As you can see the VBA7.DLL (the TargetLibrary) contains a method named rtcBeep which gets invoked whenever the VBA runtime interprets/executes a Beep keyword. The base class StubBase is responsible for telling the Verifier that an usage is being tracked, for tracking the number of invocations, …and disposing all attached hooks.
The FakesProvider disposes all fakes/stubs when a test stops executing, and knows whether a Rubberduck unit test is running: that way, Rubberduck fakes will only ever work during a unit test.
The test module template has been modified accordingly: once this feature is released, every new Rubberduck test module will include the good old Assert As Rubberduck.AssertClass field, but also a new Fakes As Rubberduck.FakesProvider module-level variable that all tests can use to configure their fakes/stubs, so you can write a test for a method that Kills all files in a folder, and verify and validate that the method does indeed invoke VBA.FileSystem.Kill with specific arguments, without worrying about actually deleting anything on disk. Or a test for a method that invokes VBA.Interaction.SendKeys, without actually sending any keys anywhere.
And just so, a new era begins.
Awesome! What else?
One of the oldest dreams in the realm of Rubberduck features, is to be able to add/remove module and member attributes without having to manually export and then re-import the module every time. None of this is merged yet (still very much WIP), but here’s the idea: a bunch of new @Annotations, and a few new inspections:
MissingAttributeInspection will compare module/member attributes to module/member annotations, and when an attribute doesn’t have a matching annotation, it will spawn an inspection result. For example if a class has a @PredeclaredId annotation, but no corresponding VB_PredeclaredId attribute, then an inspection result will tell you about it.
MissingAnnotationInspection will do the same thing, the other way around: if a member has a VB_Description attribute, but no corresponding @Description annotation, then an inspection result will also tell you about it.
IllegalAnnotationInspection will pop a result when an annotation is illegal – e.g. a member annotation at module level, or a duplicate member or module annotation.
These inspections’ quick-fixes will respectively add a missing attribute or annotation, or remove the annotation or attribute, accordingly. The new attributes are:
@Description: takes a string parameter that determines a member’s DocString, which appears in the Object Browser‘s bottom panel (and in Rubberduck 3.0’s eventual enhanced IntelliSense… but that one’s quite far down the road). “Add missing attribute” quick-fix will be adding a [MemberName].VB_Description attribute with the specified value.
@DefaultMember: a simple parameterless annotation that makes a member be the class’ default member; the quick-fix will be adding a [MemberName].VB_UserMemId attribute with a value of 0. Only one member in a given class can legally have this attribute/annotation.
@Enumerator: a simple parameterless annotation that commands a [MemberName].VB_UserMemId attribute with a value of -4, which is required when you’re writing a custom collection class that you want to be able to iterate with a For Each loop construct.
@PredeclaredId: a simple parameterless annotation that translates into a VB_PredeclaredId (class) module attribute with a value of True, which is how UserForm objects can be used without Newing them up: the VBA runtime creates a default instance, in global namespace, named after the class itself.
@Internal: another parameterless annotation, that controls the VB_Exposed module attribute, which determines if a class is exposed to other, referencing VBA projects. The attribute value will be False when this annotation is specified (it’s True by default).
Because the only way we’ve got to do this (for now) is to export the module, modify the attributes, save the file to disk, and then re-import the module, the quick-fixes will work against all results in that module, and synchronize attributes & annotations in one pass.
Because document modules can’t be imported into the project through the VBE, these attributes will unfortunately not work in document modules. Sad, but on the flip side, this might make [yet] an[other] incentive to implement functionality in dedicated modules, rather than in worksheet/workbook event handler procedures.
Rubberduck command bar addition
The Rubberduck command bar has been used as some kind of status bar from the start, but with context sensitivity, we’re using these VB_Description attributes we’re picking up, and @Description attributes, and DocString metadata in the VBA project’s referenced COM libraries, to display it right there in the toolbar:
Until we get custom IntelliSense, that’s as good as it’s going to get I guess.
TokenStreamRewriter
As of next release, every single modification to the code is done using Antlr4‘s TokenStreamRewriter – which means we’re no longer rewriting strings and using the VBIDE API to rewrite VBA code (which means a TON of code has just gone “poof!”): we now work with the very tokens that the Antlr-generated parser itself works with. This also means we can now make all the changes we want in a given module, and apply the changes all at once – by rewriting the entire module in one go. This means the VBE’s own native undo feature no longer gets overwhelmed with a rename refactoring, and it means fewer parses, too.
There’s a bit of a problem though. There are things our grammar doesn’t handle:
Line numbers
Dead code in #If / #Else branches
Rubberduck is kinda cheating, by pre-processing the code such that the parser only sees WS (whitespace) tokens in their place. This worked well… as long as we were using the VBIDE API to rewrite the code. So there’s this part still left to work out: we need the parser’s token stream to determine the “new contents” of a module, but the tokens in there aren’t necessarily the code you had in the VBE before the parse was initiated… and that’s quite a critical issue that needs to be addressed before we can think of releasing.
So we’re not releasing just yet. But when we do, it’s likely not going to be v2.0.14, for everything described above: we’re looking at v2.1 stuff here, and that makes me itch to complete the add/remove project references dialog… and then there’s data-driven testing that’s scheduled for 2.1.x…
Somewhere in the first batch of issues/to-do’s we created when we started Rubberduck on GitHub (Issue# 33 actually), there was the intention to create a tool that could locate undeclared variables, because even if you and I use Option Explicit and declare all our variables, we have brothers and sisters that have to deal with code bases that don’t.
So we tried… but Rubberduck simply couldn’t do this with the 1.x resolver: identifiers that couldn’t be resolved were countless, running an inspection that would pop a result for every single one of them would have crippled our poor little duckling… so we postponed it.
The 2.0 resolver however, thinks quite literally like VBA itself, and knows about all available types, members, globals, locals, events, enums and whatnot, not just in the VBA project, but also in every referenced COM library: if something returns a type other than Variant or Object, Rubberduck knows about it.
The role of the resolver is simple: while the parse tree of a module is being traversed, every time an identifier is encountered it attempts to determine which declaration is being referred to. If the resolver finds a corresponding declaration, an IdentifierReference is created and added to the Declaration instance. And when the resolver can’t resolve the identifier (i.e. locate the exact declaration the identifier is referring to), a null reference was returned and, unless you have detailed logging enabled, nothing notable happens.
As of the last build, instead of “doing nothing” when a reference to variable can’t be resolved to the declaration of that variable, we create a declaration on the spot: so the first appearance of a variable in an executable statement becomes the “declaration”.
We create an implicit Variant variable declaration to work with, and then this happens:
With a Declaration object for an undeclared variable, any further reference to the same implicit variable would simply resolve to that declaration – this means other Rubberduck features like find all references and refactor/rename can now be used with undeclared variables too.
Rubberduck is now seeing the whole picture, with or without Option Explicit.
The introduce local variable quick-fix simply inserts a “Dim VariableName As Variant” line immediately above the first use in the procedure, where VariableName is the unresolved identifier name. The variable is made an explicit Variant, …because there’s another inspection that could fire up a result if we added an implicit Variant.
The quick-fix doesn’t assume an indentation level – makes me wonder if we should run the indenter on the procedure after applying a quick-fix… but that’s another discussion.
A little while ago, we issued an alpha release of Rubberduck 2.0, just because, well, v1.4.3 had been around since July 2015, and we wanted to say “look, this is what we’ve been working on; it’s not nearly stable yet, but we still want to show you what’s coming”.
Time flies. 6 whole weeks, 353 commits (plus a few last-minute ones), 142* pull requests from 8 contributors, 143* closed issues, 60* new ones, 129,835 additions and 113,388 deletions in 788* files later, Rubberduck still has a number of known issues, some involving COM interop, most involving COM reflection and difficulties in coming up with a host-agnostic way of identifying the exact types we’re dealing with.
It might seem obvious, but knowing that ThisWorkbook is a Workbook object is anything but trivial – at this point we know that Workbook implements a WorkbookEvents interface; we also know what events are exposed: we’re this close to connect all the dots and have a resolver that works the way we need it to.
So what does this mean?
It means a number of false positives for a number of inspections. It means false negatives for a number of others.
Other than that, if the last version you used was 1.4.3, you’re going to be blown away. If the last version you used was 2.0.1a, you’ll appreciate all the work that just went into this beta build.
There are a number of little minor issues here and there, but the major issues we’re having pretty much all revolve around resolving identifier references, but I have to admit I don’t like unit test discovery working off the parser – it just doesn’t feel right and we’re going to fix that soon.
Speaking of unit testing… thanks to @ThunderFrame’s hard work, Rubberduck 2.0 unit tests now work in Outlook, Project, Publisher and Visio.
At first we were happy to just be able to inspect the code.
Quickly we realized “inspection quick-fixes” could be something else; some of the inspections’ quick-fixes are full-fledged automated refactoring operations. Renaming an identifier – and doing it right – is very different than just Ctrl+H/replace an identifier. Manually removing an uneeded parameter in an existing method breaks all call sites and the code no longer even compiles; Rubberduck sees all call sites, and knows which argument to remove everywhere to keep the code compiling.. and it’s much faster than doing it by hand!
Rubberduck 1.3 had Rename and Extract Method refactorings; v1.4.3 also had Remove Parameters and Reorder Parameters refactorings.
Rubberduck 2.0 introduces a few more.
The context menu commands are enabled depending on context; be it the current parser state, or the current selection.
Rename
That’s a pretty well-named refactoring. It deals with the impacts on the rest of the code base, of renaming pretty much any identifier.
Extract Method
Pretty much completely rewritten, v2.0 Extract Method refactoring is becoming pretty solid. Make a valid selection, and take that selection into its own member, replacing it with a call to the extracted code, all parameters and locals figured out for you.
Extract Interface
VBA supports interface inheritance; Rubberduck makes it easy to pull all public members of a module into a class that the original module then Implements. This is VBA’s own way of coding against abstractions. Unit tests love testing code that’s depending on abstractions, not concrete implementations, because then the tests can provide (“inject”) fake dependencies and test the applicative logic without triggering any unwanted side-effects, like displaying a message box, writing to a file, or to a database.
Implement Interface
Implementing all members of an interface (and all members of an interface must be implemented) can be tedious; Rubberduck automatically creates a stub method for every member of the interface specified in an Implements statement.
Remove/Reorder Parameters
Reworking a member’s signature is always annoying, because then you have to cycle through every single call site and update the argument list; Rubberduck knows where every call site is, and updates all call sites for you.
Move Closer to Usage
Variables should have the smallest possible scope. The “scope too wide” inspection uses this refactoring to move a declaration just above its first usage; it also works to rearrange “walls of declarations” at the top of a huge method you’re trying to cut into more manageable pieces.
Encapsulate Field
Fields are internal data, implementation details; objects shouldn’t expose public fields, but rather, encapsulate them and expose them as properties. Rubberduck turns a field into a property with only as much effort as it takes to name the new property.
Introduce Parameter/Field
Pretty much the antagonist of move closer to usage, this refactoring promotes a local variable to a parameter or a field, or a parameter to a field; if a new parameter is created, call sites will be updated with a “TODO” bogus argument that leaves the code uncompilable until an argument is supplied for the new parameter at all call sites.
More refactorings are planned for 2.1 and future versions, including Inline Method (the inverse of Extract Method), to move the body of a small procedure or function into all its call sites. Ideas for more refactorings and inspections? Suggest a feature!
This post is the second in a series of post that walk you through the various features of the Rubberduck open-source VBE add-in. The first post was about the navigation features.
Code Inspections
Back when the project started, when we started realizing what it meant to parse VBA code, we knew we were going to use that information to tell our users when we’re seeing anything from possibly iffy to this would be a bug in their code.
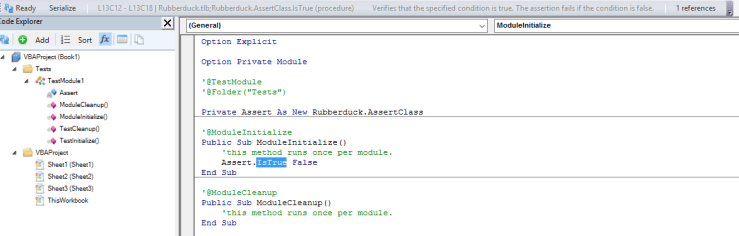
The first one to be implemented was OptionExplicitInspection. The way Rubberduck works, a variable that doesn’t resolve to a known declaration simply doesn’t exist. Rubberduck is designed around the fact that it’s working against code that VBA compiles; is also needs to assume you’re working with code that declares its variables.
Without ‘Option Explicit’ on, Rubberduck code inspections can yield false positives.
Because it’s best-practice to always declare your variables, and because the rest of Rubberduck won’t work as well as it should if you’re using undeclared variables, this inspection defaults to Error severity level.
OptionExplicitInspection was just the beginning. As of this writing, we have implementations for 35 inspections, most with one or more one-click quick-fixes.
35 inspections?
And there’s a couple more left to implement, too. A lot of inspections rely on successful parsing and processing of the entire project and its references; if there’s a parsing error, then Rubberduck will not produce new inspection results. When parsing succeeds, inspections run automatically and the “status bar” indicates Ready when it’s completed.
AssignedByValParameterInspection looks for parameters passed by value and assigned a new value, suggesting to either extract a local variable, or pass it by reference if the assigned value is intended to be returned to the calling code.
ConstantNotUsedInspection looks for constant declarations that are never referenced. Quick-fix is to remove the unused declaration.
DefaultProjectNameInspection looks for unnamed projects (“VBAProject”), and suggests to refactor/rename it. If you’re using source control, you’ll want to name your project, so we made an inspection for it.
EmptyStringLiteralInspection finds “” empty strings and suggests replacing with vbNullString constants.
EncapsulatePublicFieldInspection looks for public fields and suggests making it private and expose it as a property.
FunctionReturnValueNotUsedInspection locates functions whose result is returned, with none of the call sites doing anything with it. The function is used as a procedure, and Rubberduck suggests implementing it as such.
IdentifierNotAssignedInspection reports variables that are declared, but never assigned.
ImplicitActiveSheetReferenceInspection is Excel-specific, but it warns about code that implicitly refers to the active sheet.
ImplicitActiveWorkbookReferenceInspection is also Excel-specific, warns about code that implicitly refers to the active workbook.
ImplicitByRefParameterInspection parameters are passed by reference by default; a quick-fix makes the parameters be explicit about it.
ImplicitPublicMemberInspection members of a module are public by default. Quick-fix makes the member explicitly public.
ImplicitVariantReturnTypeInspection a function or property getter’s signature doesn’t specify a return type; Rubberduck makes it return a explicit Variant.
MoveFieldCloserToUsageInspection locates module-level variables that are only used in one procedure, i.e. its accessibility could be narrowed to a smaller scope.
MultilineParameterInspection finds parameters in signatures, that are declared across two or more lines (using line continuations), which hurts readability.
MultipleDeclarationsInspection finds instructions containing multiple declarations, and suggests breaking it down into multiple lines. This goes hand-in-hand with declaring variables as close as possible to their usage.
MultipleFolderAnnotationsInspection warns when Rubberduck sees more than one single @Folder annotation in a module; only the first annotation is taken into account.
NonReturningFunctionInspection tells you when a function (or property getter) isn’t assigned a return value, which is, in all likelihood, a bug in the VBA code.
ObjectVariableNotSetInspection tells you when a variable that is known to be an object type, is assigned without the Set keyword – this is a bug in the VBA code, and fires a runtime error 91 “Object or With block variable not set”.
ObsoleteCallStatementInspection locates usages of the Call keyword, which is never required. Modern form of VB code uses the implicit call syntax.
ObsoleteCommentSyntaxInspection locates usages of the Rem keyword, a dinosaurian syntax for writing comments. Modern form of VB code uses a single quote to denote a comment.
ObsoleteGlobalInspection locates usages of the Global keyword, which is deprecated by the Public access modifier. Global cannot compile when used in a class module.
ObsoleteLetStatementInspection locates usages of the Let keyword, which is required in the ancient syntax for value assignments.
ObsoleteTypeHintInspection locates usages of type hints in declarations and identifier references, suggesting to replace them with an explicit value type.
OptionBaseInspection warns when a module uses Option Base 1, which can easily lead to off-by-one bugs, if you’re not careful.
OptionExplicitInspection warns when a module does not set Option Explicit, which can lead to VBA happily compiling code that uses undeclared variables, that are undeclared because there’s a typo in the assignment instruction. Always use Option Explicit.
ParameterCanBeByValInspection tells you when a parameter is passed ByRef (implicitly or explicitly), but never assigned in the body of the member – meaning there’s no reason not to pass the parameter by value.
ParameterNotUsedInspection tells you when a parameter can be safely removed from a signature.
ProcedureCanBeWrittenAsFunctionInspection locates procedures that assign a single ByRef parameter (i.e. treating it as a return value), that would be better off written as a function.
ProcedureNotUsedInspection locates procedures that aren’t called anywhere in user code. Use an @Ignore annotation to remove false positives such as public procedures and functions called by Excel worksheets and controls.
SelfAssignedDeclarationInspection finds local object variables declared As New, which (it’s little known) affects the object’s lifetime and can lead to surprising/unexpected behavior, and bugs.
UnassignedVariableUsageInspection locates usages of variables that are referred to before being assigned a value, which is usually a bug.
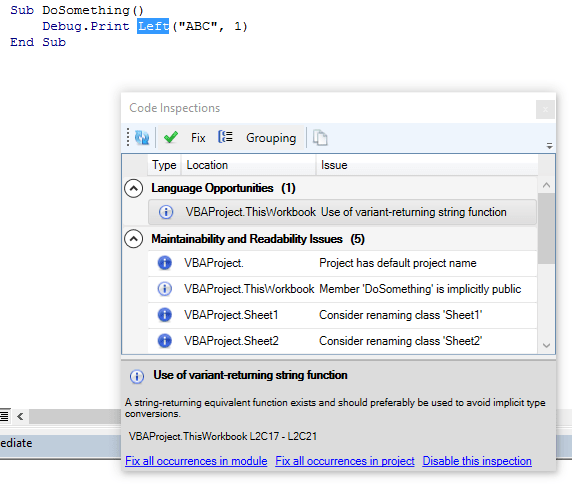
UntypedFunctionUsageInspection recommends using String-returning functions available, instead of the Variant-returning ones (e.g. Mid$ vs. Mid).
UseMeaningfulNamesInspection finds identifiers with less than 3 characters, without vowels, or post-fixed with a number – and suggests renaming them. Inspection settings will eventually allow “white-listing” common names.
VariableNotAssignedInspection locates variables that are never assigned a value (or reference), which can be a bug.
VariableNotUsedInspection locates variables that might be assigned a value, but are never referred to and could be safely removed.
VariableTypeNotDeclaredInspection finds variable declarations that don’t explicitly specify a type, making the variable implicitly Variant.
WriteOnlyPropertyInspection finds properties that expose a setter (Property Let or Property Set), but no getter. This is usually a design flaw.
Oops, looks like I miscounted them… and there are even more coming up, including host-specific ones that only run when the VBE is hosted in Excel, or Access, or whatever.
The Inspection Results toolwindow
If you bring up the VBE in a brand new Excel workbook, and then bring up the inspection results toolwindow (Ctrl+Shift+I by default) you could be looking at something like this:
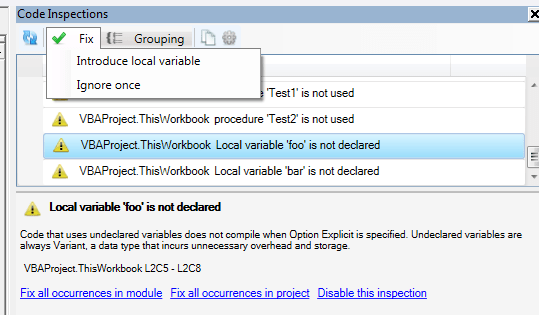
Most inspections provide one or more “quick-fixes”, and sometimes a quick-fix can be applied to all inspection results at once, within a module, or even within a project. In this case Option Explicit can be automatically added to all modules that don’t have it in the project, using the blue Fix all occurrences in project link at the bottom.
Or, use the Fix drop-down menu in the top toolbar to apply a quick-fix to the selected inspection result:
Each inspection has its own set of “quick-fixes” in the Fix menu. A common one is Ignore once; it inserts an @Ignore annotation that instructs the specified inspection to skip a declaration or identifier reference..
The bottom panel contains information about the selected inspection result, and fix-all links that always use the first quick-fix in the “Fix” menu. Disable this inspection turns the inspection’s “severity” to DoNotShow, which effectively disables the inspection.
You can access inspection settings from the Rubberduck | Settings menu in the main commandbar, or you can click the settings button in the inspection results toolwindow to bring up the settings dialog:
If you like using the Call keyword, you can easily switch off the inspection for it from there.
The Copy toolbar button sends inspection results into the clipboard so they can be pasted into a text file or an Excel worksheet.
As with similar dockable toolwindows in Rubberduck, the way the grid regroups inspection results can be controlled using the Grouping menu:
The refresh button causes a re-parse of any modified module; whenever parser state reaches “ready”, the inspections run and the grid refreshes – just as it would if you refreshed from the Rubberduck command bar, or from the Code Explorer toolwindow.
The VBE editor was last updated in 1998 – back when VB6 was all the rage, and the .NET framework was probably just a little more than a nice idea.
The VBE was just slightly less full-featured than its standalone counterpart, Visual Studio 6.0; however years went by, and the latest Visual Studio versions make the VBE look like an odd beast from another century.
Enter Rubberduck.
There are other VBE add-ins out there. For many years, VBA (and VB6) devs have loved using MZ-Tools and Smart Indenter – perhaps the two most popular add-ins ever written for the VBE. One has a lightning-fast analyzer that is capable of finding unused declarations, and even locates references in commented-out code; the other offers a highly configurable indenter that lets you instantly apply an indenting style to an entire module, or more surgically to a single procedure. What does Rubberduck bring to the table?
Lots, lots, lots of things.
This post is the first in a series of post that walk you through the various features of the Rubberduck open-source VBE add-in.
Navigation Tools
One of the most frustrating aspects of the VBE, is its limited set navigation tools. Let’s recap what the vanilla VBE gives us:
Ctrl+F / “Find” is a little more than a basic text search, that lets you search and replace text in the current procedure, module, project, or selection. Although VBA isn’t case-sensitive, you can match case, and use pattern matching, which isn’t exactly a regex search, but better than nothing.
Shift+F2 / “Go to Definition”, is actually fantastic: you can right-click any identifier and jump to its declaration – and if it’s an identifier defined in a referenced library, it takes you to its entry in the Object Browser.
Ctrl+R / “Project Explorer” is a dockable toolwindow that lists all opened projects and the modules under them, in a convenient TreeView where you can double-click on a node and navigate there.
Ctrl+Shift+F2 / “Last Position” is also fantastic: the VBE keeps a little stack of recent places you’ve been, and works like a “back” browser button that takes you back to where you were before. Quite possibly my personal favorite of all.
Bookmarks is under-used… for a reason. You can toggle any line as a bookmark, and cycle through them, but there’s no place to see them all at once.
And… that’s about it. Let’s see what Rubberduck has to offer.
Code Explorer
This isn’t the final version (we haven’t released it in 2.0 yet). When it grows up, it wants to be a full-fledged replacement for the Project Explorer. Its default hotkey even hijacks the Ctrl+R shortcut. Here’s what it does that the Project Explorer doesn’t do:
Drill down to module members, and then further down to list enum and user-defined type members.
See constant values as they appear in code.
Navigate not only to any module, but any field, enum member, constant, procedure, property get/let/set accessor, function, imported library functions and procedures.
Rename anything.. without breaking the code that references what you’re renaming.
Find all references to anything.
Indent an entire project, or a selected module.
But the coolest thing is that Rubberduck’s Code Explorer takes special comments like this:
'@Folder("ProgressIndicator.Logic")
And then renders the module like this:
That’s right. Folders. In VBA. Sure, okay, they’re not real folders – it’s a trick, an illusion… but that trick now means that with a simple annotation in every module, you can organize your VBA project the way you want to; you’re no longer forced to search for a class module among 80 others in a large project, you’re free to regroup forms together with their related classes!
This feature alone is a game changer: with it, class modules can become first-class citizen; you don’t have to fear drowning in a sea of modules, and you don’t have to give them funky prefixes to have them sorted in a way that makes it anywhere near decent to navigate.
Find Symbol
One of my favorite ReSharper features, is Ctrl+T / “go to anything”. When I realized we could have this feature in the VBE, I went ahead and did it. This simple feature lets you type the name of any identifier, and locate a specific instance of it:
This includes any variable, constant, type, enum, procedure, function, property, library function/procedure, parameter, …even line labels can be navigated to.
Just Ctrl+T, type something, hit ENTER, and you’re there. Or browse the dropdown list and click that “go” button.
Find all references
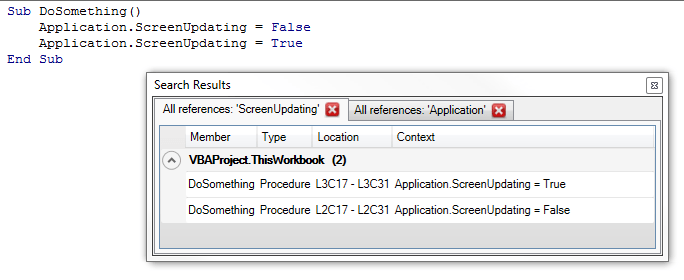
Whether you’re looking for all call sites of a procedure in your code, or you’re just curious about how many times you’re using the vbNullString built-in constant, you can right-click any identifier (at the declaration, or any of its references) and Find all references will give it to you, in a convenient tabbed search results toolwindow:
Double-click any result to navigate there.
Find all implementations
Similar to find all references (its results use the same toolwindow), this one is also one of my favorite ReSharper features, that Rubberduck simply had to implement. It’s only useful when you’re coding against abstractions and implementing interfaces (if you didn’t know… yes, VBA code can do that!) – but then, it’s the best way of navigating to implementations of an interface class or member.
For example, here I added two new class modules, added this line in each, and then implemented the members:
Implements ProgressIndicator
After refreshing the parser state, I can right-click the Execute method in my ProgressIndicator class, select “Find all implementations”, and get this:
TODO Explorer
Rubberduck can (well, does actually) spot special markers in comments, and lets you navigate them in a dockable toolwindow – again, double-click navigates there:
Take that, bookmarks! You can group them by marker or by location.
By default, Rubberduck will mark NOTE, TODO and BUG as interesting, but you can always configure it to whatever suits your needs in the Todo Settings tab of the settings dialog:
Regex Search & Replace
Okay, that one’s not really there yet. But it’s totally on the roadmap, and definitely coming in a future version of Rubberduck. Take that, search with pattern!
Whew! That covers Rubberduck’s navigation features. What do you think?
I first noticed this strange behavior when I refactored Rubberduck’s menu system last summer: although I was 100% certain that there only ever was a single instance of a given menu item, in the Click event handler the sender object’s GetHashCode method returned a different value every time the handler ran.
GetHashCode, in the “normal” .net world, is tightly related to the Equals implementation – whenever you override Equals, you must also override GetHashCode. The value returned by this method is used by data structures like Dictionary and HashSet to determine some kind of “object ID” – the rules are simple:
if two things are equal (Equals(...) == true) then they must return the same value for GetHashCode()
if the GetHashCode() is equal, it is not necessary for them to be the same; this is a collision, and Equals will be called to see if it is a real equality or not.
In the “normal” .net world, it’s usually safe to assume that an object’s hash code doesn’t change throughout the lifetime of the object – because a correct implementation relies on immutable data.
Apparently COM Interop has different rules.
When Rubberduck parses the projects in the VBE, it generates a plethora of Declaration objects – thousands of them. There’s a Declaration object not only for every declared variable, procedure, property, parameter, constant or enum member, but also one for every VBComponent, and one for each VBProject – anything that has an identifier that can appear in code has a Declaration object for it. Declarations are related to each others, so any given Declaration instance knows which Declaration is its “parent”. For example, a module-level variable has the declaration for the module as its parent, and the declaration for that module has the declaration for the project as its parent.
On the first pass, there’s no problem: we’re just collecting new data.
Problems start when a module was modified, and is now being re-parsed. The parser state already has hundreds of declarations for that module, and they need to be replaced, because they’re immutable. And to be replaced, they need to be identified as declarations that belong under the module we’re re-parsing.
A module’s name must be unique within a project – we can’t just say “remove all existing declarations under Module1”, because “Module1” in and by itself isn’t enough to unambiguously qualify the identifier. We can’t even say “remove all existing declarations under Project1.Module1”, because the VBE has no problem at all with having two distinct projects with the same name.
In Rubberduck 1.x we used object equality at project level: if a declaration’s Project was the same reference as the VBProject instance we were processing, then it had to be the same object. Right? Wrong.
And this is how we got stumped.
We couldn’t use a project’s FileName, because merely accessing the property when the project is unsaved, throws a beautiful COMException – and we could be facing 5 different unsaved projects with the same name, and we needed a way to tell which project that modified “Sheet1” module belonged under. We couldn’t use a project’s hash code, because it was now known to be unreliable. We couldn’t use… we couldn’t use anything.
This COM Interop issue was threatening the entire Rubberduck project, and shattered our hopes of one day coming up with an efficient way of mapping a parse tree and a bunch of Declaration objects to a VBComponent instance: we were condemmned to constantly scrap everything we knew hadn’t changed since the last parse, and re-process everything, just to be 100% sure that the internal representation of the code matched with what the IDE actually had.
What about hi-jacking one of the R/W properties that are never going to end up user facing? Like .HelpFile? Just copy the original hashcode to the property and then search for it.
Genius!
Rubberduck 2.0 will hijack the VBProject.HelpFile property, and use it to store a ProjectId value that uniquely identifies every project in the IDE.
Problem solved! Nobody ever writes anything to that property, right?
Stay tuned, we’re just about to announce something very, very cool =)
I’ve been working on quite a lot of things these past few weeks, things that open up new horizons and help stabilize the foundations – the identifier reference resolver.
Precompiler Directives
And we’ve had major contributions too, from @autoboosh: Rubberduck’s parser now literally interprets precompiler directives, which leaves only the “live” code path for the parsing and resolving to work with. This means you can scratch what I wrote in an earlier post about this snippet:
[…] Not only that, but a limitation of the grammar makes it so that whatever we do, we’ll never be able to parse the [horrible, awfully evil] below code correctly, because that #If block is interfering with another parser rule:
Private Type MyType
#If DEBUG_ Then
MyMember As Long
#Else
MyMember As Integer
#End If
End Type
And this (thoroughly evil) one too:
#If DEBUG_ Then
Sub DoSomething()
#Else
Sub DoSomethingElse()
#End If
'...
End Sub
Rubberduck 2.0 will have no problem with those… as long as DEBUG_ is defined with a #Const statement – the only thing that’s breaking it is project-wide precompiler constants, which don’t seem to be accessible anywhere from the VBIDE API. Future versions might try to hook up the project properties window and read these constants from there though.
Isn’t that great news?
But wait, there’s more.
Project References
One of the requirements for our resolver to correctly identify which declaration an identifier might be referring to, is to know what the declarations are. Take this code:
Dim conn As New ADODB.Connection
conn.ConnectionString = "..."
conn.Open
Until I merged my work last night, the declarations for “ADODB” and “Connection” were literally hard-coded. If your code was referencing, say, the Scripting Runtime library to use a Dictionary object, the resolver had no way of knowing about it, and simply ignored it. The amount of work involved to hard-code all declarations for the “most common” referenced libraries was ridiculously daunting and error-prone. And if you were referencing a less common library, it was “just too bad”. Oh, and we only had (parts of) the Microsoft Excel object model in there; if you were working in Access or Word, or AutoCAD, or any other host application that exposes an object model, the resolver simply treated all references to these types and their members, as undeclared identifiers – i.e. they were completely ignored.
I deleted these hard-coded declarations. Every single one of them. Oh and it felt great!
Instead, Rubberduck will now load the referenced type libraries, and perform some black magicCOM reflection to discover all the types and their members, and create a Declaration object for the resolver to work with.
This enables things like code inspections specific to a given type library, that only run when that library is referenced:
It also enables locating and browsing through references of not only your code, but also built-in declarations:
Doing this highlighted a major performance issue with the resolver: all of a sudden, there was 50,000 declarations to iterate whenever we were looking for an identifier – and the resolver did an awful job at being efficient there. So I changed that, and now most identifier lookups are O(1), which means the resolver now completes in a fraction of the time it took before.
There’s still lots of room for improvement with the resolver. I started to put it under test – the unit tests for it are surprisingly easy to write, so there’s no excuse anymore; with that done, we’ll know we’re not breaking anything when we start refactoring it.
One of the limitations of v1.x was that project references were being ignored. Well, the resolver is now equipped to start dealing with those – that’s definitely the next step here.
Module/Member Attributes
Another limitation of v1.x was that we couldn’t see module attributes, so if a class had a PredeclaredId, we had no way of knowing – so the resolver essentially treated classes and standard modules the same, to avoid problems.
Well, not anymore. The first time we process a VBComponent, we’re silently exporting it to a temporary file, and give the text file to a specialized parser that’s responsible for picking up module and member attributes – then we give these attributes to our “declarations” tree walker, which creates the declaration objects. As a result, we now know that a UserForm module has a PredeclaredId. And if you have a VB_Description attribute for each member, we pick it up – the Code Explorer will even be able to display it as a tooltip!
What about multithreading?
I tried hard. Very hard. I have a commit history to prove it. Perhaps I didn’t try hard enough though. But the parser state simply isn’t thread-safe, and with all the different components listening for parser state events (e.g. StateChanged, which triggers the code inspections to run in the background and the code and todo explorers to refresh), I wasn’t able to get the parser to run a thread-per-module and work in a reliable way.
Add to that, that we intend to make async parsing be triggered by a keyhook that detects keypresses in a code pane, parsing on multiple threads and getting all threads to agree on the current parser state is a notch above what I can achieve all by myself.
So unless a contributor wants to step in and fix this, Rubberduck 2.0 will still be processing the modules sequentially – the difference with 1.x is the tremendous resolver performance improvements, and the fact that we’re no longer blocking the UI thread, so you can continue to browse (and modify!) the code while Rubberduck is working.
What’s left to do for this to work well, now that the parsing and resolving is stabilized, is to allow graceful cancellation of the async task – because if you modify code that’s being parsed or resolved, the parser state is stale before the task even completes.