The v3 full rewrite failed, obviously. The project was simply too ambitious for the limited capacity of an open-source weekend project.
Rubberduck is at a crossroads: either there’s a way forward, or sooner or later it’s a way to the graveyard.
You thought this was going to be about Rubberduck going “on indefinite pause”, didn’t you? If you haven’t seen the recent movement around the project’s website and GitHub organization, I wouldn’t blame you for thinking so, but…
I can’t let that happen to Rubberduck. This project means too much to me, to just let it die like this.
Not after all the blood, guts, and sweat that went into it.
It’s 2026. VBA has been “dead” for what, 20 years now? It’ll be “dead” for another 15 and Microsoft will still do nothing about modernizing VBA: they’ve essentially left that ground to the community – and that’s us.
And I’m perfectly fine with that.
I have no idea how big or small Rubberduck’s user base is; all I have is rough estimates. I know the total number of installer downloads for any given release tag, that’s all. I never collected any data from our users, because an OSS project that can’t sign their code shouldn’t be doing that, plus where’s the infra and who’s paying for it? I’ve poured quite a lot of my own money into this over the course of the past decade or so, and Enterprise-approvable, certified/signed code is crazy expensive and simply wasn’t going to happen under a pure open-source GPLv3 model at my sole expense.
Meanwhile we’ve built a reputation for ourselves and are now positioned as the reference for professional-level VBA code, and Microsoft’s own flagship AI tool – Copilot – spontaneously names Rubberduck as the best tool in the ecosystem in 2026 and validates our unit testing features as a unit testing framework that is comparable to industry-standard NUnit/JUnit. To me it says something about how deep the actual reach goes, and how dead VBA actually still isn’t.
“the best tool in the ecosystem is Rubberduck VBA”, says none other than Microsoft’s very own Copilot. Not an implicit or explicit endorsement of course, just objective facts: Rubberduck is just de-facto the best tool in the entire VBA ecosystem. The mission is accomplished.
Are we done beating around the bush now?
Yes: I’m going all in.
Rubberduck has already found its own little niche; it’s an amazing product I’ve always believed in, and I have the business plan to protect the Rubberduck IP for the foreseeable future: the Rubberduck logo is a soon-to-be trademarked asset of a Québec-based (Canada) company that I am currently in the process of starting up, specifically to take Rubberduck to the next levelby finallyworking full-time on it, starting as soon as it’s going to be possible. Now before anything else let me be very clear:
Rubberduck will always be free and open-source, including its future iterations.
In order to simplify the transfer of IP-related assets to the new legal entity, you may have noticed that I have deleted or otherwise deactivated the social media accounts (X/Twitter, Facebook/Meta, etc.), along with the Ko-fi and PayPal accounts. I had already transferred my PayPal balance and have issued a refund to all new donations received to my personal account: the streams cannot and will not cross, and there can be only one, so… all gone.
This blog will be archived. Being a Québec-Inc. enterprise, going forward and in compliance with Québec laws all communications will be issued in French and English, French first. DNS registration for rubberduckvba.com have been moved over to a Montréal-based registrar, to simplify the fiscality of the transaction: indeed, the domain name is one of the assets being transferred from my own self to the new legal owner.
Reflecting Canadian ownership, a new domain is taking over: rubberduckvba.ca will now be served instead of the historical .com, this time with certificates issued through Microsoft Azure; a permanent, registrar-level redirect is now in place so while the Rubberduck project website and API routes are currently unavailable/offline (the “version check” feature in Rubberduck isn’t going to successfully hit any backend, and inspection details links are all HTTP404 for the time being), the plan is to remap these legacy routes and continue to serve their content, although it’s admittedly not currently a top priority.
The GitHub repositories have been archived. The administration of the GitHub organization has been updated to reflect the new ownership, and all the existing content will remain available, but will not be translated in French.
It’s the end of this blog then?
Depends how you see it, really. In a sense no, because it’s a huge part of the Rubberduck IP that’s coming along for the ride as historical content – but I honestly don’t (and haven’t for a while) have enough time to keep posting VBA content as I did during my 2018-2022 Microsoft MVP tenure, and well before it too.
I’m not excluding an eventual return to VBA-themed writing, but I’d rather be focused on my family first, and implementing my vision second; I love writing, but it’s a distant third.
So… What’s next?
I can’t yet disclose what’s next, actually. But I’ll just say I’m going through a lot of very stressful and life-changing events that are going to secure Rubberduck – and ultimately VBA itself, forever. Mark my words:
This company will make VBA immortal.
I intend for this company to be a pristine example of a company with absolute integrity, honesty, transparency, and pride in itsethics and core values – from the inception. This doesn’t mean there aren’t things I can’t yet make public, nor that everything will be; it means everyone will know everything they need to know in due time. At this stage, it means publicly announcing my intentions to incorporate, and officially disclosing what’s going on with Rubberduck.
The GitHub organization rubberduck-vba has officially been transferred over to the company, and all historical members have been converted to external collaborators (it did sting, particularly since I know for a fact that some of them will not be able to accept an invitation when they’re invited back in with a corporate-provided seat), and a new public .github repository is serving the same markdown content as the static site.
Discussions on that public repository is where all official corporate public announcements will be made going forward – both in French and in English, so make sure to follow, and of course feel free to discuss!
I know it’s been forever, trust me… I know. But life happens as they say, and here we are a whole year and over 20,000 downloads later with some movement at last in the Rubberduck repository.
Also… Rubberduck is now officially a whole 10 years old! It’s completely incredible how far we’ve pushed this project, and I’m very proud of everything we did, undid, redid. The number of times we’ve collectively crashed the VBIDE together must overflow an Integer by now!
Development on the project started late in 2014, but the website and blog only did in early 2015, with the initial release of what was then not much more than an extension of a thought experiment.
The “official” 2.5.92 release will come later once it’s been out in the wild a little as a pre-release, but the announcement will refer to this present article for what’s new.
The broken website did not like having the new tag records inserted for some reason, but the fallback links point to the right place so it’s still relatively easy to find the installer download; you’ll find the executable listed under the assets of the latest release/tag on GitHub:
A handful of new inspections are being introduced once again, this time around Option Base 1 and a little pet peeve of mine with Excel-specific code.
Parameterless Cells
As you know, in the Excel library Range.Cells is a parameterized get-only property that accepts a row or column index, or both, …or neither. Except when it’s not parameterized, it’ll just return exactly the parent Range object reference, making it an entirely superfluous member call. This new Excel-specific inspection will flag these parameterless calls. A quickfix could be implemented to automatically remove these calls, but flagging them as redundant is a good first step:
Public Sub DoSomething()
Debug.Print Sheet1.Range("A1").Cells.Address '<<< inspection result here
End Sub
UPDATE 2025-02-01: Properly implementing this inspection requires more careful consideration that make it difficult to avoid false positives in the few specific situations where a parameterless Cells call does, actually, return different references depending on what other Range members were called before – this kind of tracking isn’t quite possible with v2.x, unfortunately. So this inspection isn’t making it to release, it’s been removed already.
When Option Base 1 is specified, implicitly sized arrays begin at index 1 instead of the more typical 0. However, ParamArray arrays will always be zero-based regardless of Option Base. Similarly, explicitly qualified VBA.Array function calls will also systematically yield a zero-based array. This new inspection flags these parameters and function calls as having a base that is inconsistent with the Option Base setting of the module. There’s no fix for this one either, it’s just a hint that could potentially help detect off-by-one errors.
Option Base 1
Public Sub DoSomething()
Dim Values As Variant
Values = Array(42)
Debug.Print LBound(Values) '<~ 1 as per Option Base
Values = VBA.Array(42) '<<< inspection result here
Debug.Print LBound(Values) '<~ not 1
End Sub
Another example:
Option Base 1
Public Sub DoSomething(ParamArray Values) '<<< inspection result here
Debug.Print LBound(Values) '<~ not 1
End Sub
Rebalanced Inspection Defaults
For a while now, something had been bugging me about the inspection types and default severities: things tended to stick to the default fallbacks over time, and the categorization of a number of inspections felt wrong and overall unbalanced. Because inspection types are for legacy reasons part of the inspection configuration, if yours isn’t the default configuration you will not see an effect until you either reset everything to defaults, or manually edit the configuration file to remove everything about inspections.
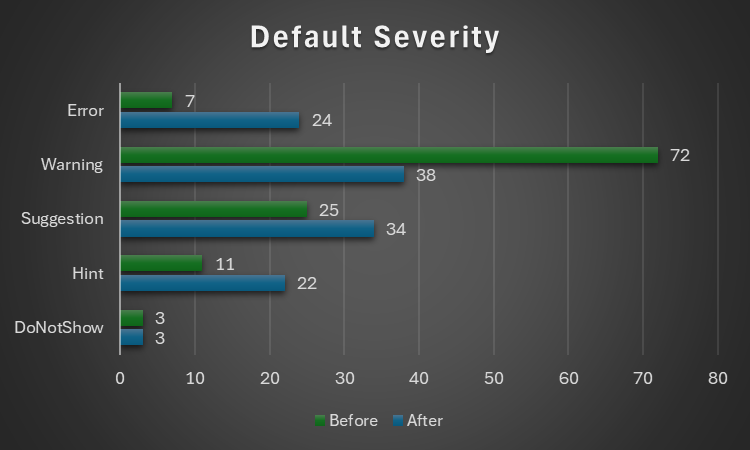
Here’s the breakdown of how things were shuffled around with inspection types:
Inspection Type
v2.5.91
v2.5.92
Code Quality
73
60
Language Opportunities
23
21
Naming and Conventions
19
28
Rubberduck Opportunities
3
12
Total
118
121
..and with the default severity levels:
Default Severity
v2.5.91
v2.5.92
DoNotShow
3
3
Hint
11
22
Suggestion
25
34
Warning
72
38
Error
7
24
Total
118
121
Notably, everything around annotations is now under Rubberduck Opportunities, and default severity levels are much more sensible; the 3 inspections disabled by default remain disabled:
RedundantByRef mirrors ImplicitByRef; both are valid takes, just different conventions and the more explicit one was made the default, but you can reconfigure them to match your style by enabling one and disabling the other.
StepIsNotSpecified mirrors RedundantStepOne; again both valid stances, this time with the less noisy one as the default configuration.
ShadowedDeclaration was disabled for performance reasons, if I recall correctly. Or it’s something about some difficult false negative situations making it somewhat too unreliable or experimental to ship enabled by default.
This clean-up touched every single inspection, and in the process the way to localize the resources has been standardized, which should fix the annoying partly-localized labels in some inspection results.
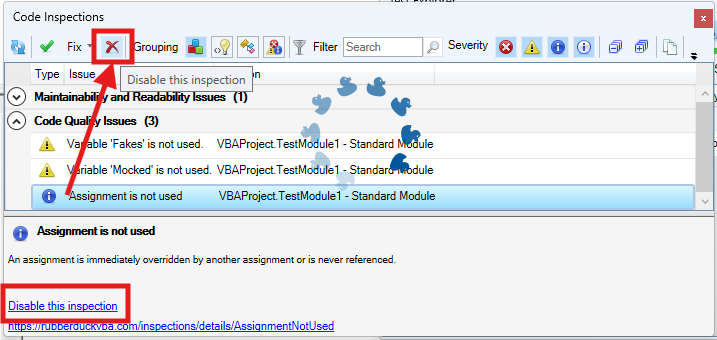
The inspection results toolwindow gets a new disable this inspection button right next to the Fix menu, which should make it easier to disable an inspection altogether with a single click, by selecting any of its results in the grid.
The “disable inspection” command remains available as a link/button in the bottom panel, but now also as a more prominently visible button on the main toolbar. Note that there is no confirmation prompt for this actionfor now.
Unit Testing
This is a very, very exciting release for the unit testing feature!
Performance Enhancements
Keeping the Test Explorer UI updated with a constantly changing source collection was taking a serious toll on the UI thread, incidentally the only one available for running VBA code. Thanks to a quick PR by contributor tommy9, the explorer now leverages WPF features that improve the situation.
Projects with a lot of tests can still significantly speed up their execution by hiding the toolwindow and selecting Run all tests from the Rubberduck menu. If the main thread isn’t busy drawing a UI element, it’s free to run the instructions of a test procedure.
Moq+VBA
Seven long years after the initial pull request was opened, it’s finally merged and ready to start a little revolution in the VBA unit testing world.
There are important limitations: user code cannot be mocked after it’s been modified, and the setup of ByRef parameters may not always work correctly, but the bulk of it is close enough (and has been for a long time) to be release-worthy. Part of what took so long was that we wanted to ship the full feature working exactly as intended, but there are some serious technical roadblocks and between entirely dropping a 7 years old pull request and merging it anyway, … I’m going with the merge. Perfect is the enemy of good, they say.
What’s happening here is nothing short of pure wizardry: we’re turning arbitrary COM objects into .net ones, and then we translate configuration calls written in VBA into .net expressions that literally get compiled and invoked on the fly to call the non-generic methods offered by Moq 4.8 (getting a bit old, but we’ve never had anything like this in VBA).
In other words, unit testing with Rubberduck now empowers you with quite a large part of what only becomes possible with a real mocking framework, which this is.
The mocking API is currently documented in the wiki, but here’s the crux of it… it’s a game changer:
'arrange
Dim Mock As Rubberduck.ComMock
Set Mock = Mocks.Mock("Excel.Application") 'here we create a new mock using the Excel.Application progid
'then we configure our mock as per our needs...
Mock.SetupWithReturns "Name", "Mocked-Excel"
Mock.SetupWithCallback "CalculateFull", AddressOf OnAppCalculate
Dim Mocked As Excel.Application
Set Mocked = Mock.Object 'ComMock.Object represents the mocked object and always implements the COM interface it's mocking
'act
'just making sure the mock works 🙂
Debug.Print Mocked.Name
Mocked.CalculateFull
'assert
'use the ComMock.Verify method to fail the test if a method that was setup was not invoked as per the test's specifications:
Mock.Verify "CalculateFull", Mocks.Times.AtLeastOnce
There’s only a handful of simple objects to work with, and the API is clean, unambiguous, intuitive. The example above illustrates the enormous power that’s now in your hands by mocking the Excel.Application interface.
The COM mock lets you access the proxy object to pass it around as a surrogate implementation for a dependency that would otherwise compromise the “unit” part of it being a “unit test”; it’s a class type that’s spawned into existence from its definition, for which you can setup any member call in a test. Here we make the `Name` property return a different value just because we can, and when the macro invokes the `CalculateFull` method against this mock instance, rather than awaiting a full application-level compute you can simply verify that the method was invoked, or run a callback procedure (elegantly passing it to the API with the `AddressOf` operator) that can be parameterized if you need to accordingly alter some state.
I’ll write a whole article dedicated to this API soon, but together with the Fakes API, this really takes the Rubberduck unit testing feature to the next level (code coverage would be the next one). As long as you can identify the dependencies in your code (and come up with a way to inject them from the caller), you can now write a test that abstracts them away.
Other Tweaks
The Unassigned variable usage inspection will now honor the out prefix by convention, meaning it will no longer issue false positives when a variable is assigned by another procedure via a ByRef argument, as long as it’s named accordingly with an “out” prefix.
The About box will now mention “Win11” for Windows builds above 22000, even though the major version says 10. This was likely related to Rubberduck using an ancient .net Framework API to retrieve this OS version information.
Renaming an enum member in a way that requires the constant to be qualified, will now correctly use the enum type name rather than the name of the containing module, which was an edge case that could cause headaches and break the code.
What about v3?
If things had gone smoothly, you would know by now. They obviously haven’t, and not much has moved on that front since last May or so. I’m not abandoning the project, but building an entire editor client and a language server is honestly much more than I can chew at the moment, for multiple reasons… twinBASIC is coming, and while a commercial offering, it’s a VB6/VBA language server and compiler, and it reckons the whole editor part is already a solved problem. Rubberduck 3.0 was going to reinvent that wheel, which would have been a huge distraction.
So RD3 is going to be re-scoped a bit: the planned VBIDE integration / add-in part remains of course, but instead of making an entire editor from scratch, we’ll integrate into an existing, modern one that’s already an extensible LSP (Language Server Protocol) client, much like Visual Studio Code (but no, it’s not going to be VS Code). This instantly knocks off (well, removes outright) a gigantic, milestone.
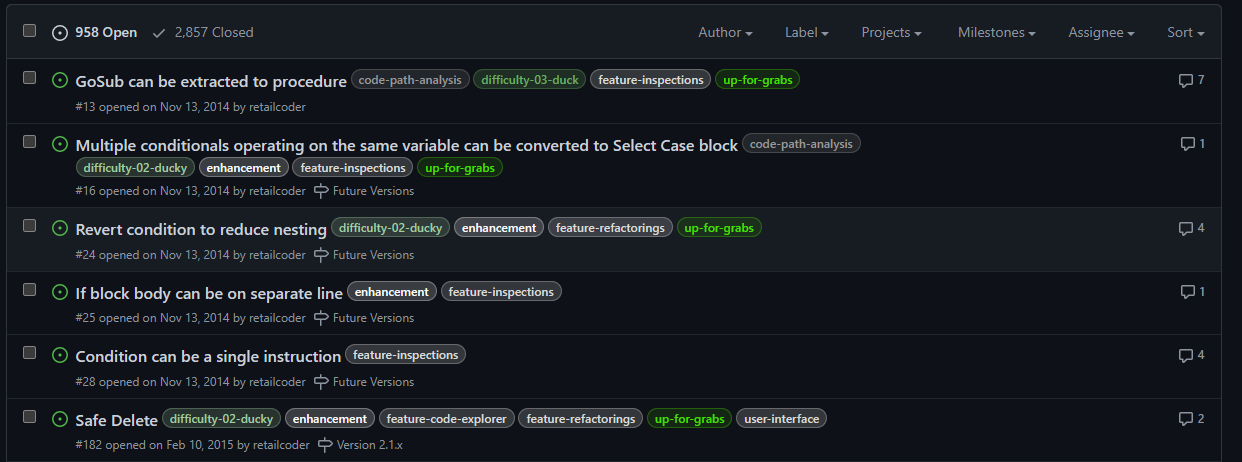
With this v2.x release, the backlog of pending pull requests is finally cleared. 950+ open issues remain in the Rubberduck repository, but very few are actual unresolved bugs or realistically implementable feature ideas. Expect additional pull requests for missing translations, minor fixes and UI/UX enhancements, but the 2.x life cycle is now essentially completed… and it was about time: the technology used for building Rubberduck has evolved a lot in the last decade, with much of it either deprecated, or on the brink of falling out of official long-term support from Microsoft, which is making it harder and harder to easily and successfully build Rubberduck, hoping with fingers crossed that nothing breaks at every dependency update.
I bet VBA will outlive .NET Framework 4.8.1 LTS, which is non-ironically very funny to me… but for Rubberduck to keep moving forward, making the move from the now ancient .NET Framework over to current technology is inevitable – and development on v3 has already knocked that critical milestone, too.
Afterthoughts
I want to stop spreading too thin and actually finish the website now (as you can see, …the thing is falling apart!), and then with Rubberduck 2.x in its current state (more or less), I can finally draw a line and know exactly what v3.0 needs to be. My priorities have shifted quite much since 2021 for many reasons, and Rubberduck and the blog and my online presence in general basically had to hit the brakes. Life happens… doesn’t it.
I’ll always write code as a hobby, as I’ve done ever since I found out about programming. But I also played (badly) some guitar as a teen, and carried a few harmonicas with me to the Microsoft MVP Global Summit in 2018 and 2019 (the two I attended before they went virtual during the pandemic); these days I feel like I could write about the music theory I’ve learned since, or perhaps how to configure the reed gaps on a 10-hole diatonic, standard Richter-tuned harmonica to make it easy to play the hidden overblow notes. I haven’t been paid to maintain a line of VBA code for a very long time now, and I’ll always love it but I can’t say it’s my GoTo language anymore, but it’s all right – Rubberduck isn’t written in VBA anyway. But it’s becoming hard to find inspiration to write about some random VBA things, especially since I’ve stopped participating on Stack Overflow. I stopped, because they basically made an agreement with OpenAI and essentially stole (with a unilateral move in violation of the agreed-upon license) the volunteer work and helpful knowledge-dumps of tens of thousands of people (myself included) to train a… chatbot and make billions off of these people’s work, and then take art and reduce it a prompt.
I mean I get it, it’s fun. But it’s a very steep cost just for something that’s just innocent fun.This is the first and last AI-generated image you’ll ever see from me on this blog.
Perhaps I’m just turning into an old man screaming at a cloud (brought to you by AWS!), but… look, it doesn’t matter that you can prompt a machine to play some harmonica for you: you’ll never, ever, ever experience any AI-generated slop like when you’re actually playing the blues and counting that I-IV-V progression over these 12 bars. Same on guitar. Same on drums. Same with code.
Last time I wrote here, the language server was just barely starting to be able to communicate with the editor client, and the editor was displaying content but while content could be modified, it wouldn’t notify the server about it yet. Since then a lot has happened in both the editor client and the language server, and the server is now actually parsing the workspace/project files, issuing some diagnostics (syntax errors (LL) and SLL parser failures), and it returns folding ranges when the client asks for them.
The editor itself has seen a few tweaks; the “ducky button” idea might have been superseded by a new markers margin that could conceivably anchor context menus for code actions.
The first diagnostics issued by RD3 originate directly from the parser itself: SLL prediction mode failures are deemed hints, and LL mode failures are either syntax errors… or grammar bugs.
I’m happy with just something showing up at this stage; icons in the margin render on the correct document line as it’s scrolled up and down, but they don’t refresh properly on document change yet. Similarly, additional work is going to be needed around foldings, but so far it’s looking great and everything that should work, does.
Foldings are going to work, too, including ranges using custom @Region/@EndRegion annotations!
Settings
The settings dialog has received quite a bit of attention lately, and I’d almost consider it release-ready now. Features include:
Back/forward navigation buttons
Filtering the current view
Searching across all settings
Reactive layout that rearranges tiles as the dialog is resized
Expand any setting group to a full-page view
Asynchronous validation for URI settings (both file:// and http/s:// URIs)
Opening the dialog for any particular setting key, which is how the cogwheel icons everywhere are going to be bringing up the settings dialog.
Typing in the search box automatically filters items in the current view; the “search” command creates a new view with the search results from all setting groups. Navigation commands are featured on the left, and a reset command on the right.
The debate around whether settings should automatically be saved to disk as they are modified has been settled: we drop the Apply button, and keep all changes in the UI until the dialog is okayed, which means the settings dialog of RD3 is going to behave very similarly to the one in RD2, except we’re also dropping the Apply button, leaving just Accept and Cancel.
Each modified setting value is listed in the details of a confirmation message that is shown after settings are serialized to the file system, unless the message is disabled, of course. Missing resource keys have since been added ☺️
Search results include a label that says which setting group it belongs under, which is great because lots of similarly-purposed settings have similar names and descriptions:
Even with identical names and descriptions, you know exactly what you’re looking at because the parent setting group is shown at the bottom right of every search result.
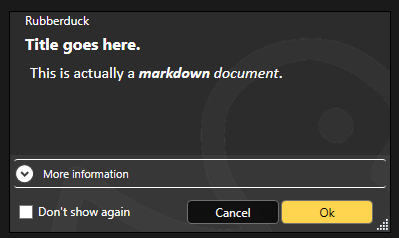
Another thing of note, is that RD3 has now dropped its custom markdown-enabled WPF message box in favor of native task dialogs:
Task dialogs have everything we need: custom buttons, icons, captions, a checkbox in the footer, …a footer, collapsible details, and more.
This move takes a whole entire headache away by outright eliminating a potential source of annoying bugs, while ensuring RD3 messages are reliably shown, and show everything we need them to show.
Each message shown in RD3 is going to have an associated key, and this key is how “do not show this message again” is going to be saved as a setting value under the General/DisabledMessageKeys setting (a setting whose value is a list of strings).
Server Side
Work on the server side has taken a bit of a backseat while I was working on the client, so while it’s parsing all code files in a workspace/project, collects and resolves a type for all member symbols in both referenced libraries and the current workspace, and even issues diagnostics for syntax errors and SLL failures, that’s still not enough to even begin to think about feature parity with Rubberduck 2.x; additional work is needed to collect and resolve hierarchical symbols (i.e. everything inside procedure scopes) and issue semantic tokens to the editor client, which would enable semantic colorizations aka syntax highlighting, and on the server side unlocks the level of static code analysis we need. We could technically already have client-side, regex rule-based highlighting, but knowing that it’s 1) wholly insufficient and 2) bound to be overwritten by the semantic tokens, adding it now just isn’t worth it.
Editor
The editor is now notifying the server when a document is opened, closed, or modified, but it also needs LSP wiring for when a document is saved, and well it actually needs to write the modifications to the physical workspace folder (aka “save”). The Workspace Explorer is currently showing files that exist in the workspace folder but aren’t included in the project, but there’s no command to include a file into (or exclude from) the active project, so my next task should be to do with the Workspace Explorer what I just did with the settings dialog, and revisit everything it’s supposed to be able to do (in an alpha release anyway) – and make it happen.
With the language server issuing member symbols, the editor client is now well behind in terms of what it does vs what it coulddo. Off the top of my head, the following tooltabs/features can be started now, since all the data they need is available:
Code Explorer
Object Browser
Properties
Find Symbol
As for the editor itself, its combo boxes are still empty, but with member symbols resolved we could actually populate them, including listing WithEvents variables and implemented interfaces.
Project Planning
If you’ve been following all along, you know this part isn’t my preferred one, but as you can see from the above, RD3 is quickly expanding its capabilities and will soon have so much “ready to sprint” work piled up, I won’t be able to knock it all down by myself and will have to write down a brain dump of what’s left to do and in what priority order.
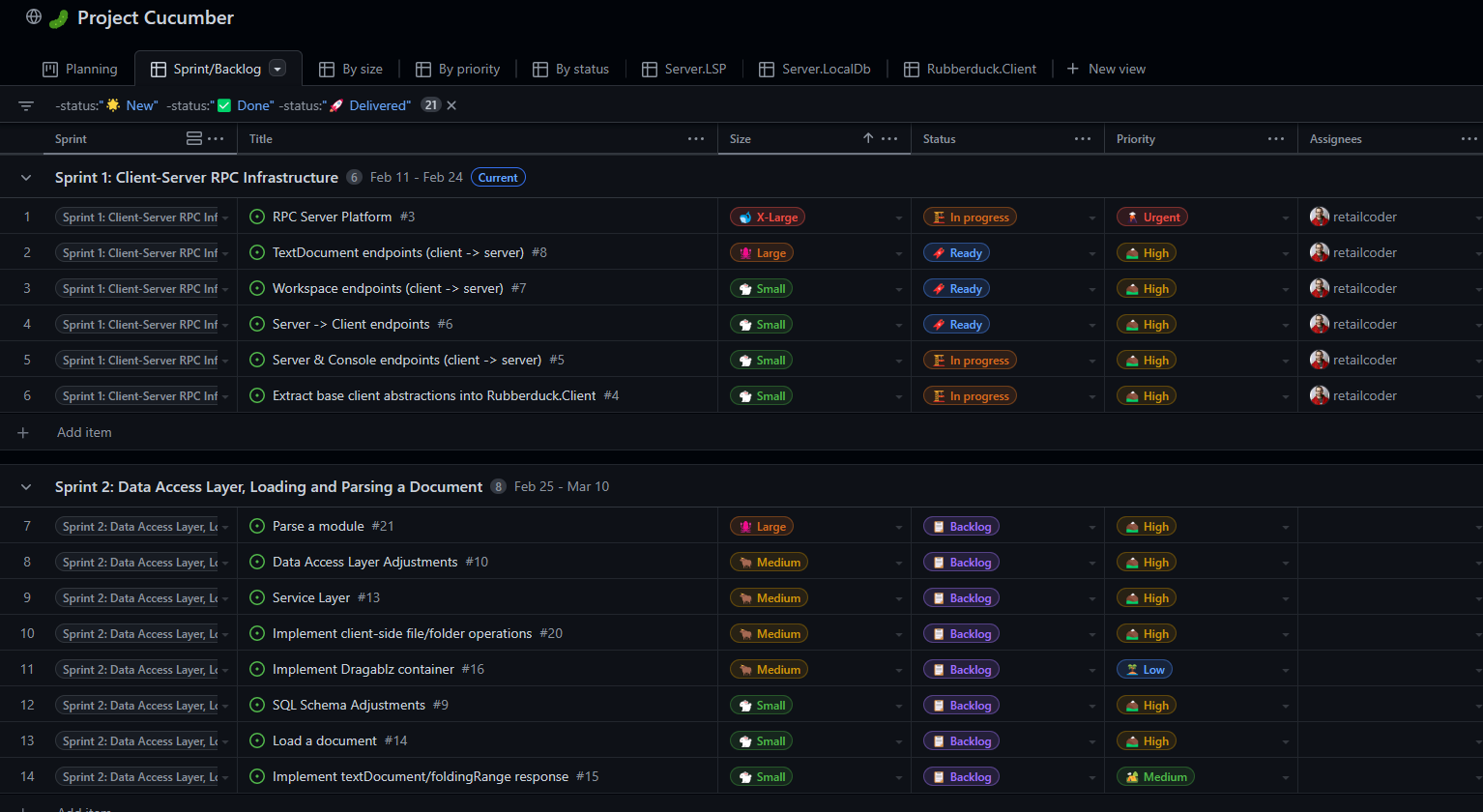
I went ahead and archived last year’s Project Cucumber on GitHub, and created a new GitHub project linked to specific RD3 projects – so there’s a board for the language server with a ticket for every LSP handler it needs to implement, and then there’s a completely distinct board for the editor client, and another one for the update server, and there’s one for the addin too, and another one for an eventual RD3 subdomain on rubberduckvba.com, and so on.
And then there’s a separate project/board that’s a bug tracker that encompasses all the projects.
Next Steps
The number of things that can be worked on is increasing as the foundational groundwork solidifies, and the next step for the project is becoming more and more the next step for me; we’re reaching a point where a meaningful backlog can start being maintained and this means the next step for me has to be to come up with some documentation for what’s there, to help would-be contributors find their way in the RD3 solution. And then I’ll get back to UI work, so the next update should have some interesting screenshots!
About a year ago, I came to the conclusion that it would not be realistic to refactor Rubberduck into a client/server architecture and to incrementally make the 2.x internal model work with the Language Server Protocol (LSP), which had been established as a target for 3.0.
To get the ball rolling I started a new project from scratch, and started writing a prototype to explore the AvalonEdit API for the client/editor part. The server side took longer to take off, because I simply dived head-first into the LSP specification, and hit a blocker with socket transport (which was the most efficient way to do this): it would pop an elevation prompt, and requiring admin rights to connect to the language server process was a complete showstopper, and then that’s about when I took my attention to the OmniSharp library… which implemented JsonRPC and LSP a million times better than I ever would have, and made my entire prototype model moot, so I happily scrapped it all and started over, and here we are.
Transport works over named pipes, with bidirectional JsonRPC (Remote Procedure Call) messages; JsonRPC is essentially a specification for formatting/structuring messages between processes (hence client/server), and LSP builds on top of it: OmniSharp deals with all this boilerplate for us.
A year later there’s a VBE add-in that’s just a menu with a few intriguing commands, like “Show Editor” and “New Workspace”… and nothing else. Rubberduck 3.0 will only have minimal interactions with the VBIDE, which is the polar opposite of what Rubberduck has been doing so far. As a result, the RD3 memory footprint in the host process is absolutely minimal, and the main/only thread of the host process is consequently very much left alone, unless the add-in is creating or synchronizing a workspace. This removes an entire, rather populous group of things that can potentially insta-kill the host process, making it the most stable Rubberduck add-in we could ever come up with. You can’t blow up the host process if you’re not crashing in the host process! That said knock on wood still… the VBE is life, it… finds a way.
The show editor command brings up the Rubberduck Editor, starting it if it isn’t already running. It’s a standalone Windows Presentation Foundation (WPF) application that runs in its own separate process, so if something terrible happens and the editor crashes, the add-in can just spawn a new one and carry on as if nothing happened. The editor app is a JsonRPC server here, and the add-in/host process is its client.
When the editor opens or creates a workspace/project (the add-in sends a URI as a command-line argument), it starts a language server process (another separate process!) and sends it the text content of all opened documents.
When the server process completes initialization, it reads the text content of all workspace documents that aren’t opened in the editor, and starts the parser pipeline.
In RD2 it’s a `RubberduckParserState` object that holds all the (mutable) state; in RD3 the (immutable) state consists of hierarchical symbols, some of which can resolve to a type – and they’re held in an ExecutionContext that maintains a symbol table and can copy itself into an ExecutionScope, …and you can already tell it’s a whole different beast.
Rubberduck 2.x was already doing something quite similar while pre-processing the precompiler directives, and the unreachable case inspection makes use of it… While impressive, it’s tacked on top of the parser rather than being the parser.
It all goes back to a fateful evening of 2014 when I somehow stuck with the idea that all Rubberduck needed was declarations, and then we’d resolve identifier references and have something to work with. Over the years that followed we made good use, and pushed the limits of this naive model that mangled the concepts of symbols and types into a catch-all declaration that could just as well be a class module or a line label.
So now we’re going to be resolving the type of symbols, and instead of lookup dictionaries giving us the declarations of a particular module, we get hierarchical symbols that simply know what their child symbols are, and a symbol table that contains everything that’s in scope inside the module member we’re looking at.
In other words, we’re going to be a few things short of an actual interpreter (not linking external types, for one), but more than close enough to be issuing diagnostics rather than inspection results.
Parser Pipelines
I recall when we retro-fitted cancellation capabilities into the RD2 parser, and made it asynchronous: in 3.0 the thing is asynchronous by nature, as it builds on top of the .net Task Parallel Library, but this time everything is happening inside Dataflow, a more abstract library that goes further than tasks and wraps them into “blocks” that connect to each other to move state through – so we start by giving it a `WorkspaceUri`, and then the pipeline gets (or creates) the current document state for each document in that workspace, and then depending on parallelization settings it can dedicate a thread to each document.
So far that’s implemented differently and more robustly, but conceptually the same thing happens in RD2. What happens once we have a syntax tree for each document is different though.
In RD2 we would be collecting all declarations and storing them in the DeclarationFinder, a service that the resolver uses to get resolution candidates – and that many other features use whenever they need to find a declaration.
In RD3 we’ll be collecting symbols in two distinct traversals of each module’s syntax tree. The first pass collects the member symbols, which includes everything in the declarations section of the module and each procedure scope, including its parameters; the second pass collects all the remaining symbols inside each procedure.
The declaration finder is not making it to v3: instead, each workspace is given an execution context, where a hierarchical symbol table is maintained. During the first symbol pass, this context gets all the module and member symbols, and once all modules have been traversed we resolve a VBType for each typed symbol, so the second pass has all the information it needs to resolve a VBType for all the remaining symbols.
As the syntax tree traversal enters a procedure scope, the context generates an execution scope, which is essentially a stack frame that has its own scoped symbol table, which only includes symbols that are accessible to the procedure we’re in. When the traversal exits the procedure, the resolved symbols are copied from the execution scope before the scope is dismissed; when the module has been completely traversed, all the resolved symbols get copied to the workspace’s execution context.
Once all workspace symbols are resolved, a semantic pass will be able to traverse each executable scope to issue various diagnostics.
A visual representation of how the pipeline dataflow blocks are currently interconnected.
The part that collects symbols from referenced libraries still needs to be ported from RD2, but I’m not worried about that part at all.
Current Status
As of this writing, most of the pipeline itself is done; what needs attention now is the exhaustive list of all possible semantic tokens, which is how the editor/client is going to be able to implement semantic syntax highlighting – the second symbol resolution pass needs to tokenize the syntax tree, and then the resulting tokens need to be sent to the client. But first, I need to categorize every single one of them. LSP specifies a handful of common kinds of tokens, but the default kinds are insufficient to correctly tokenize VBA code. Moreover, because semantic tokens responses are typically rather large, for performance reasons what’s sent to the client isn’t the tokens themselves, but an integer that represents it: a legend has to be crafted to map these integer IDs to semantic tokens on the client side.
Once that’s done, I’ll be wiring it all up and make the server start processing a workspace whenever one gets opened, …and to start processing a code file whenever it gets modified in the editor. Then the client can handle the server notifications about workspace symbols and semantic tokens being refreshed (and possibly even diagnostics).
Errors and Diagnostics
Now that’s another massive paradigm shift. Work hasn’t started on these yet, but we can already tell that RD3 inspections aren’t going to “run” per se. Rather, diagnostics are to be issued by the semantic pass, when the executable symbols are being interpreted within an execution scope.
Inspections that RD2 dubs parse tree inspections would become diagnostics issued during the initial traversal of the parse trees, along with syntax errors – i.e. error nodes in the parse tree. The hardest part of this is going to come up with an error message that makes sense: if you’ve experienced parser errors in Rubberduck before, you know these error messages require a very deep understanding of the parser rules to make any kind of sense, and turning these into human-friendly errors is a very difficult task that will likely not be completed by the time 3.0 is released. That said, last year’s prototype has confirmed that the editor will be able to render them as squiggly lines that show a tooltip when hovered; similar to modern editors, hovering diagnostics will pop a ducky button that lists all available code actions aka quick-fixes (and refactorings) for that diagnostic, if any.
Phase II
With the language server resolving symbols, the project is entering a new phase: in the next couple of weeks/months, RD3 will become much more than a glorified Notepad, and will start feeling more and more like an actual IDE. With access to the symbols, the editor can now implement all the features, so the rest is a matter of coming up with a decent backlog, and let the relentless march towards the first Rubberduck 3.0 alpha 1 release begin!
Last time I said I was going to be working on a Workspace Explorer user interface, so that I have a toolwindow to play with as I work on the toolpanel layouts and docking functionality.
And I did exactly that, so while it’s far from being ready for an alpha release, it’s there and it does exactly what it needs to do, up to and including opening document tabs in the editor.
I also added control templates for different document types, so editing a .MD markdown document is done in a differently-configured editor than when editing a VBA source file.
The markdown document editor handles read-only documents by only presenting the preview pane.
Workspace Explorer
The toolwindow has acquired context menus and commands to create a new project, to open an existing one, and to synchronize the workspace with the VBE; it is configured to be shown docked on the left side by default. I’m developing the editor as a standalone application, so for now VBE synchronization is set aside until JsonRPC communications happen over named pipes – which is going to be needed at one point or another; there’s just no need to have 3-way communications going on right now.
It already supports opening multiple workspaces/projects, although additional analysis is needed to work out exactly how that’s going to work with VBE synchronization (there is a concept of an “active” project/workspace that will probably be useful for this).
The content of a workspace is represented in the explorer by a tree view that lists all the files and folders under the “.src” source root folder. Document nodes (whether they’re source files or not) can be opened in the editor by double-clicking, or selecting “Open” from the node’s context menu.
The context menu when you right-click anywhere in the background area offers new and open commands to create a new project/workspace and open an existing one, so already the UI is taking a direction where there are multiple ways to discover a command, which I believe is a good thing in an IDE application.
Since a workspace represents the project, the explorer toolwindow also needs commands to create, delete, cut, copy paste, and rename files & folders, as well as the ability to include/exclude files/folders from the project, and to move things around, preferably by simply dragging and dropping the tree nodes. Dropping a file (or files, or folders) from Windows Explorer into the tree view should ultimately copy (or move?) the dragged items into the workspace folder, and then there needs to be a command that simply opens the workspace location in Windows Explorer.
These are well beyond what’s needed for an alpha release though, so I’ll likely just iron out a few wrinkles and let it be for a while: we can open workspace files in the editor, and it’s really all I need it to do… for now.
Eventually it will need a horizontal template that would be the default view when the toolwindow is docked at the bottom (or could serve as an alternative view when docked on the sides).
Shell Layout
The editor shell is divided into sections. There are two collapsible panels on either side, and a third at the bottom; all panels can be resized as needed by dragging their outer border, and each panel houses tooltabs that show tab headings at the bottom; only the document panel will display them at the top.
Even without tearable tabs, the layout would be usable as-is. As I’m writing this update though, my focus is on getting the InterTabClient to understand where I mean to have my content – after I re-dock an undocked tab, the content ends up being rendered in the tab headers, ..and then a NullReferenceException brings down the process as soon as something moves.
At this stage toolwindows are abstract enough that adding one for the Language Server Trace went very well – and that particular toolwindow is itself very abstracted too, such that adding Editor Trace and Update Server Trace toolwindows will be a breeze. In fact adding any new toolwindow is very simple.
The ThunderFrame control has been augmented with a pin button that all toolwindows have, that makes the parent collapsible panel remain open when the mouse leaves it. The font size has decreased a bit and the icons were scaled back to 16×16 for a tighter look and to yield more screen estate to the actual content. I’ve switched back to the light theme to see how much damage the dark theme adjustments did, and it’s not too bad: seems only the scrollbars’ buttons have suffered.
The background ducky has been severely toned down and is much more subtle now; it’s also been removed from the main window background, and the code editor template background isn’t letting it through either. It’s still there if you care to look for it, but it’s not an obnoxious distraction anymore.
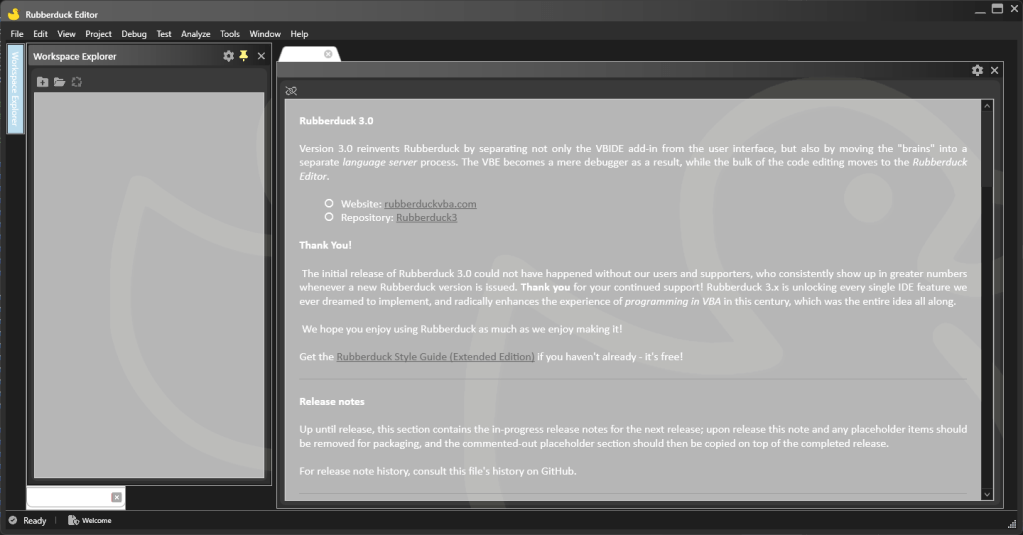
Welcome.md
By default, RD3 will automatically open a read-only markdown document named Welcome.md; this document is not part of any workspace, and will include useful links and detailed release notes including new features, enhancements and bug fixes, broken down by component (editor, language server, add-in, etc.).
Maintaining this file whenever a pull request is merged will make it much easier to put together a release and communicate “what’s new?”.
This document is the first document type to be supported, because it stands on its own and contrary to source files, once it loads and renders, it’s essentially feature-complete which makes it a quick win. Every other document is going to involve the workspace, so it made sense to get that one out of the way right away.
It also makes a good place to put release notes; each merged RD3 pull request will be listed there along with a short description of the new feature, enhancement, or bug fix.
The “welcome” document contains release notes and additional information about the release.The code editor is barely a Notepads surrogate at this point; in the next few weeks it’ll get all the features that don’t involve the LSP server.
The template for a read-only markdown document is only showing the preview pane; editable markdown documents can collapse the pane to the right or resize it as needed (perhaps eventually re-dock it). Links are currently not working in the preview (not much effort has gone into this editor yet), but the idea is to allow navigating links when the option is enabled (and it would be disabled by default). The markdown document is already binding its font family from the ViewModel, which is a precursor to a bunch of editor settings that the code editor will want to have as well.
Status bar
The prototype-era status bar has been removed and properly templated to reflect the current editor state:
Only a simple icon and status label will be shown until a workspace/project is loaded. The icon will reflect the connection status of the language server, and bring up the language server trace toolwindow when clicked.
When a workspace is opened, the status bar label might show a small progress indicator tracking the server-side processing going on in the LSP process; the editor is immediately fully responsive and usable.
Cancellable server operations can be cancelled by clicking a button that appears next to the progress indicator when cancellation is possible.
When at least one editable document tab is opened in the editor, the status bar template changes to show the caret location, among other useful bits of information pertaining to the active document tab.
Next Steps
With the editor shell foundation in place, the next client-side features are going to start needing data from the language server, so now is a good time to take a step back, tidy things up, and make sure everything in place works as intended; document and address any pending bugs before adding new tooltabs and potentially creating more work than necessary.
Glitches with docking need to be resolved, the UI for tooltabs isn’t right, closing tabs should notify the language server, context menu commands need to be implemented to undock tooltabs, and frame headings should be draggable; little things left and right. The editor itself needs basic editing commands and a context menu; a toolbar will probably be useful, too.
Oh, and then I need to flip back to the dark theme, because working with the light one has done funky things… I need to revisit all the themes before it gets any worse:
Or perhaps I could “fix” it by just renaming it “xray-dark” or something, and then just shelve this until theming gets some real attention?🤔
And then LSP gets serious.
Update 2024-01-02: LSP communications over named pipes are now working; the problem was that the initialization was being performed twice.
Swag Shop 2024
The swag shop I opened this year is going to keep going in 2024. I’m brewing a number of RD3 design ideas, and I’d like to have embroidered hats and hoodies made.
Ko-fi supporters spending $1 or more get access to supporter-exclusive content; as I work on RD3, I upload screenshots and small posts about upcoming stuff, before it’s even pushed to GitHub.
I’m planning to start writing a complete RD3 user guide in 2024, that’ll probably end up as a PDF download alongside the Style Guide.
I bought way too much inventory in 2023, so expect extra free goodies in every shop order!
Release 2.5.9 came with an unfortunate bug where an exception in the version check feature would blow everything up and fail the startup of the add-in. It was of course quickly fixed in a subsequent pre-release build, and meanwhile other enhancements have been merged, so here we are with a new release that fixes the error handling of the version check service and correctly parses empty instructions.
One parser bug was reported through an interesting edge case that was reminiscent of good old ThunderCode, looking something like this:
If condition Then:::::::::::DoSomething
It is of course grammatically correct, which means Rubberduck should be able to ingest it. Thanks to yet another contribution by @MDoerner this version correctly parses such empty instructions, which feels like it opens up an opportunity for an inspection that flags them, and a quick fix to remove them.
This parser tweak is definitely making it to RD3!
Other Hacktoberfest contributions include:
Correctly replacing any Exit Sub with Exit Function statements when converting a Sub procedure into a Function.
Fixing an unsafe conversion from Char to Int that was causing a crash in PowerPoint 2019.
COM Interop / RCW handling solidifying shutdown by taking measures to ensure reading or writing a CommandBarButton’s caption or enabled state does not happen during shutdown / after the COM objects have been destroyed.
Allowing multiple line continuations before the dot operator in member access expressions.
Version Check Bug
That one is purely on me rushing to release without realizing that the web API call wasn’t surrounded by a try/catch block, and since it was an asynchronous operation… any uncaught exception would take down the host process, which is utterly uncool.
The fix was, obviously, to handle errors around the network I/O. Of course a simple work-around was to simply disable the version check on startup, but unless you’re familiar with Rubberduck configurations, tweaking these without being able to load Rubberduck in the VBE to bring up the settings dialog wasn’t exactly a user-friendly experience.
Note: the web API that refreshes the website and responds to version check requests is still down! I’ve manually inserted the database records for this release, so it shows up on the website.
Extract Method
There’s an off-by-one selection glitch with this refactoring that’s also getting fixed in this release, thanks to a timely contribution by @tommy9. This selection glitch was disabling the refactoring command when it shouldn’t be disabled, making it more difficult to use than it should be.
RD3 Progress
Meanwhile I’ve been giving quite a bit of love to v3, working on the new settings model and UI. I needed to get settings out of the way early on, because everything wants to access the configuration settings, including the locations of the server executables: I got to a point where hard-coding these was no longer practical, and since debug builds don’t generate the assemblies in a single “install folder”, being able to point them to local debug builds was a good excuse to get the settings model under way.
Data Driven UI
Historically in Rubberduck, adding a new setting meant adding a property to one of the setting groups, crafting a dedicated UI section for it in the settings UI, and then editing a .XML configuration file to define the defaults. All this work means adding a new setting is a whole undertaking in its own right, and that’s essentially a deterrent to liberally sprinkling configurable options any time we come across a decision and go “hey it would be nice if this was configurable!”.
RD3 treats settings at a different abstraction level: instead of having a “GeneralSettings” class with a property for each setting, we go meta and now GeneralSettings is becoming a settings group, and the individual settings are becoming record type instances, where each setting has a name, a description, a data type, default and current values, and additional metadata to identify hidden settings that should not appear in the dialog (e.g. the flag indicating whether Rubberduck prompted to import legacy indenter settings), or settings that are recommended to keep their default value (e.g. server executables’ locations).
Because there are settings of pretty much every data type, templating the settings UI before everything else means everything else gets to use already-templated controls, resulting in a consistent UI that looks and behaves the same across the entire application.
The still-WIP RD3 settings dialog showing some language client settings.
Unless it’s for a new data type that wasn’t already templated, adding a new setting in RD3 means adding a new record class for the setting, defining its default value and metadata in the same place, and then adding an instance to an existing setting group – and that’s all there is to it… well, excluding the associated string resources, each of which will need translations (most of this doesn’t exist in RD2).
Language Server Protocol
The VBE addin itself is implementing a LSP client, but its server is going to be the Rubberduck Editor process: the editor will be notifying the addin whenever it needs to synchronize source files into the VBE. In other words the editor is both a server and a client, depending on whether it’s talking to the addin or to the language server.
At this stage the addin is initializing a language client when it launches the editor, and as soon as the editor completes the LSP initialization handshake with the addin, it starts the language server process and initializes its own language client.
While both the addin and the editor implement LSP initialization, the two processes have vastly different responsibilities: the addin doesn’t deal with documents, and doesn’t care about semantic tokens or diagnostics: its primary responsibility is to get the code files into and out of the hosted VBA project, and provide an insulation layer between COM and the rest of Rubberduck. The editor however, is going to implement most of the LSP-defined features.
All Json-RPC communications are happening across process standard I/O for now, but this isn’t viable because when the editor talks to the addin, it needs to do so in a channel that’s separate from when it talks to the language server (things could get really funky otherwise). Named pipes will solve this, but in order to keep things moving forward I’ve opted to leave the addin behind (it’s almost completed!) and build the editor as a standalone application (which greatly simplifies debugging). We’ll get the named pipes working to implement the synchronization with the VBE, but the VBE is otherwise not needed for now, so standard I/O it is, and we’ll look into named pipes when they’re needed.
Project Templates
As I was piecing together everything I needed to serialize the .rdproj file and initialize a workspace, I came across the need to create a blank project that references the VBA library… and as I was hard-coding this sensible default I realized I could just copy an existing project file instead of hard-coding it, and things snowballed from there a bit, and so RD3 will come with a default empty project that references the VBA library, but also templates for various Microsoft Office hosts, and then why not have a template for a host-agnostic MVP project!
In Visual Studio when you start a new ASP.NET MVC project, you get a bare-bones working application that’s already somewhat organized, with the source files under specialized folders; the RD3 Rubberduck Editor will be able to do the same.
Creating a new project in the Rubberduck Editor lets you pick a project template and not start from scratch every time.
Templates are just special folders with folders and code files; all the folders under the Templates folder are considered project templates!
Project/workspace files solve the problem of “remembering” which files were opened, so it should be easy to restore them – the same feature is how template projects will open in the editor with the README.md document tab opened.
Folders
Making VBA code as git-friendly as possible is, I believe, one of the best ways to ensure VBA lives on; being able to organize a VBA project into actual folders is an important part of this, but the lack of namespaces makes it a challenge… that’s solved with the .rdproj file. Indeed, it makes a way to ensure no RD3 project can have two source files that result in importing a module into the VBE… and then overwriting it when importing the next source file.
Taking RD2 @Folder annotations as a baseline, the relationship between modules and folders is reversed in RD3: RD2 folders were just a representation of where modules fit in a tree, folders could only exist if there was a module to define it. Now that we’re moving to the file system, a project can have empty folders, and modules don’t (can’t) have a say on what folder they live under.
This poses a compatibility problem with RD2 projects, that we’re going to address by acknowledging the RD2 annotations and migrating the project to the RD3 paradigm by creating actual folders under the project workspace, and moving the source files there; the @Folder annotation comments should then be removed. This functionality is not implemented yet despite the “new project” command being completed, because it’s the language server that will tell the editor about this when it starts issuing diagnostics… and we’re not there yet.
Forward
Rubberduck 3.0 can now create a new project, load an existing one, and save workspace changes to the file system. Loading a workspace/project loads all the file contents in memory in the editor process, and that’s where we’re at: the next step is to come up with a UI to explore the files in a workspace and pick one or more to actually open in an editor tab. This workspace explorer UI is similar to the VBE’s project explorer in that it knows everything there is to know about what files are in a project, and what content is in each file… but unlike the RD2 code explorer it knows nothing about any semantics, so it doesn’t/can’t drill down to member level – it’s really all about files and folders.
Once the Workspace Explorer UI is done, I’ll be focusing on the editor shell UI again, this time to work on the docking panels and document tab system: then we’ll have the infrastructure in place to add all the toolwindows we need, and document tabs that – finally – actually display file contents… whether that’s a markdown document, a plain text file, or a VBA source file.
Opening a workspace has implications with the LSP server: when you open a project in the editor, it sends everything it knows about these files to the server process through Json-RPC communications – the server process never accesses the files directly; files “belong to” the editor process.
Progress has been a bit scattered, but steady. The shell now supports theming and Rubberduck 3 will ship minimally with light/blue, light, dark, and dark/blue themes, currently essentially copied and adapted from Visual Studio and VS Code color palettes. I’ve hit a bump on the road trying to get fancy with the window chrome controls, but I’m going to be putting that aside if I don’t get to a satisfying solution soon.
Light/blue theme with an empty editor shell.Dark theme in the exact same state.Dark/blue theme mirrors VS Code’s “Abyss” theme.
With the envisioned chrome, the title bar would blend with the menu bar, and the window commands at the right would also match the theme. Obviously that’s far from a showstopper!
With theming out of the way, the editor shell looks fabulous but is still far from completed. The client area where the giant ducky outline logo is currently shown, is where the editor actually needs to have its docking panels and document tab host – the outline logo will have to be moved there if it’s to be visible at all when everything is done.
Because of license compatibility issues, the AvalonDock library which would be the natural go-to option since the actual editor tabs will be AvalonEdit controls, cannot be used. As an alternative with a compatible license, rather than developing our own docking panels and MDI layout, we’ll be using the Dragablz library and its Dockablz layout panels.
Document Types
The prototype 6 months ago only covered one aspect of the editor – the code editor. But Rubberduck 3.0 will need to have the ability to edit more than just VBA code.
In VBA a project is embedded in its host document and consists of the VBProject component modules; in RD3 a VBA project lives on disk, and Rubberduck knows what project files are to be synchronized with the VBE, but there’s nothing stopping it from being able to include additional files which don’t synchronize back to the VBE but can be useful for development.
Plain Text
RD3 will create a .rdproj (“Rubberduck Project”) file in the workspace folder. That file is going to be a plain text (JSON) file, and we want the editor to be able to open and edit it. Eventually there might be a dedicated language server that understands JSON syntax as a language (and then .rdproj files can get syntax highlighting, section folding, completion, etc.), but that will not be a priority at first – what will be, is just to ensure we can load such text files in the editor.
Markdown
Text files with formatting; markdown (.md) format is essentially today’s tech for what used to be done with RTF – in other words, they’re formatted text files, but instead of an obscure RTF syntax it’s all done with plain ASCII characters, just like on GitHub, Stack Overflow, and Jira.
And this is great news, because then having the ability to render markdown in XAML means we get to format other things that used to be strictly plain text – like message boxes:
The language server can also supply such formatted content for tooltips and parameter info, so there’s a non-zero chance @description annotations in RD3 can even honor such formatting when present in docstrings.
The editor shell will support editing and rendering markdown documents, so your project can include a README.md file that you can edit and preview directly in the editor.
It also makes a nice document type to display a startup/”welcome” tab that describes the latest features after an update, again a bit like Visual Studio does.
VBA Code
Text files that the editor understands to be Classic-VB code files (this will have to be based on their respective file extensions) that contain the code for VBProject components that may or may not belong to the workspace of the project that’s in the VBE. Because we’re working off exported files and a .rdproj tells us what libraries are referenced and where to go find what modules for that project, we can now also edit “orphaned files”, as we are no longer constrained to editing code files that belong to the host project!
.rdproj, and consequences
Among the many challenges in RD2, was the fact that we wanted to avoid cluttering our users’ files with any kind of non-code metadata. For example at one point an idea was floated around for hijacking just one single module and having it contain nothing other than commented-out project metadata. Or perhaps carrying this metadata in a file alongside the host document. None of these approaches were going to be enjoyable to use, so instead RD2 dropped the idea of having any per-project configurations, because in RD2 the host document is the single source of truth.
That’s one of the many things changing with v3.0: because the truth has moved outside of the host document and into workspace folders, we now have a per-project physical location to put Rubberduck metadata in.
If we are to hope for feature parity with 2.x, the add-in needs to tell the language server about the project, including the location of referenced libraries. In RD2 we would simply acquire the project references and proceed to extract the types and members, but the language server in RD3 knows absolutely nothing about COM and does exactly zero interop with the VBIDE – so we needed a way to pass the information along without twisting the LSP in ways that would make it impossible for clients other than the Rubberduck Editor to use our language server. Not that it’s a requirement, but the idea is to do things right, not just to make it work for our purposes: if we strictly adhere to the language server protocol (LSP) specifications, then at least in theory it would be simple to write an addin client for any other LSP-capable editor, including VSCode. It’s not a target to write such a client, but having the possibility to do it is.
So rather than coming up with a way to serialize that information and pass it to the server through custom initialization parameters (the protocol defines an “additional data” dictionary that could theoretically be used for this), the addin will generate and maintain a .rdproj file whenever it exports source files to the workspace.
This “Rubberduck Project” file will contain basic information such as the Rubberduck version, a URI for the project root, and then a URI for each library reference (or perhaps just a ProgID string? Or a GUID representing its CLSID? All of the above? 🤔 TBD) and another URI for each module in the project. This isn’t completely final because it’s pretty much just about to be implemented, but the idea would be to end up serializing to a file that would look something like this:
Of particular note are the document module supertypes, which is information RD2 manages to collect from in-process ITypeInfo pointers that the language server in RD3 isn’t going to have access to, by virtue of running in an entirely separate process.
This means the RD3 addin has the following responsibilities:
Connect/Disconnect the VBIDE host;
Import/Export modules into the VBE and workspace folders;
All debugger functionalities;
Execute Rubberduck unit tests (VBA code);
Collect any ITypeLib/ITypeInfo metadata that can be collected for a VBProject.
Start/Shutdown the Rubberduck Editor;
That’s quite a lot already, and these bullet points already make it clear that the single responsibility of the Rubberduck.dll library must encompass every single interaction with the VBIDE, including the native Office CommandBar controls.
It’s a lot already, but that’s the complete extent of it – which means RD3 connects and loads as a VBIDE addin when the VBE starts up, …but then it doesn’t need to resolve the entirety of Rubberduck at startup, which means a splash screen isn’t even warranted here because we’re completely loaded and good to go in the blink of an eye, and it’s (mostly) not even because of dotnet 7! In other words, RD3 restores the Alt+F11performance and sharpness you know and love.
The last bullet in the list is why: the VBE loads the RD3 VBIDE add-in, and uses JsonRPC messages to communicate with the Rubberduck Editor process. The editor in turn starts the language server, and each process runs in its own separate silo while running periodical “health checks” to ensure there’s still a client process on the other end – if a server loses its client, it shuts down; if a client loses its server, it can just start a new one and carry on without much disruption.
The addin becomes a lightweight launcher that extends the VBE by exposing menu commands that pop an “About” box, or start the Rubberduck Editor app. It wouldn’t be outside of its scope to also launch update and telemetry servers, and since the settings are shared between all processes, a command to bring up Rubberduck settings could be in-scope as well.
Next Steps
Work on the Rubberduck Editor is only getting started! Without thinking too far ahead, here’s what’s to come:
Window chrome controls and resize thumb
Put everything together to serialize .rdproj
“New Rubberduck Project” dialog UI
Import/export VBProject commands
Document tab host
Docking panels, side/tool panels
“Welcome” markdown document tab
Open/close text and other document types
Save, save as commands
Settings dialog UI
About dialog UI
And then that’s just what can move forward to completion in the Rubberduck Editor part without the server side – but we’ll cross that bridge when we get to the airport, as they say.
Both telemetry and update server applications have their skeletons done and can be started and debugged just like the language server.
Update Server
By running this server separately from the rest, we can get RD3 to update itself without needing to leave the VBE or close the host application and everything you’re working on: if the update server is so configured, it can tell the addin to shut down, which in turn shuts down the Rubberduck Editor, which shuts down the language server.
At that point none of the Rubberduck libraries are in use, and the update server can overwrite them with a newer version before instructing you to manually load the Rubberduck addin which again starts pretty much instantly.
This only requires that we package and ship the update server separately from the addin… kind of like how Visual Studio does.
Telemetry Server
One of the things we want RD3 to address, is just getting basic feature usage information so there’s data out there to help diagnose and prioritize any issues. Logging in RD2 is pretty extensive and verbose already, but it’s very organic and missing in some places; in RD3 logging is built into the base classes for every server-side handler, and with requests coming in asynchronously we need a better way to track what entries belong to which request, and this is exactly what telemetry logs do. The telemetry server will be fully configurable and will never transmit any PII information anywhere. As it handles telemetry events, this server serializes and enqueues telemetry payloads; the queue can then be reviewed, filtered, manually transmitted or cleared, or it can be configured to transmit periodically in batches – the receiving end will be hosted on api.rubberduckvba.com, and there’s a storage concern that may require severely limiting how much data we can keep around and aggregate (probably going to need to sample the data / reject most payloads!), but that’s a concern for another day.
Ultimately the goal is to surface the entire dataset through some explorable dashboards, charts, and tables on the website, so everyone can see what data is being collected: exactly none of it is going to be a secret.
The language server will be able to send language-level telemetry data, on top of everything else that’s useful for debugging. Aggregating this data would allow us to expose how our users are using VBA, from simple metrics like the number of modules in a project to interesting tidbits such as the average number of expressions in a conditional, or what kind of loop constructs people use the most (e.g. While…Wend vs Do…Loop), whether our users declare and fire custom events, implement interfaces, …anything we can think of, really. This obviously isn’t a priority, but it’s been on my mind ever since I heard the Microsoft Excel product team mention they haven’t got the slightest idea of what people do with VBA: seen by the right eyes this data could, ironically, eventually possibly contribute to achieving feature-parity in the VBA alternatives being developed by Microsoft… or rest the case that VBA cannot be taken away because what people do with it involves things that aren’t going to be supported in prospective so-called alternatives (looking at you, OfficeJS).
Development of Rubberduck 3.0 continues, stay tuned for updates, as I’ll be posting here all along the journey.
Things were moving pretty fast with the prototype, but moving on to the actual LSP-driven project hit a roadblock as far as actually achieving the cross-process JsonRPC communications. I put it aside for a while, hoping to get back to it later, and then summer arrived and real-life stuff kept me busy. Renovations in Rubberduck, renovations at home.
Wow time flies, pretty much six months have elapsed since the last status update, and now it’s Hacktoberfest again already! So what happened?
RPC Issues
For about five of those six months, not much moved forward, but ideas kept brewing all along, and the RPC issues have now been resolved.
So, where’s RD3 at?
Clean Start, Clean Exit
When the VBE loads RD3, the add-in starts a separate language server process and connects to it through the language server protocol (LSP), using the very same technology that Microsoft put in VSCode, via the OmniSharp libraries. When the add-in is unloaded from the VBE (whether manually or as the host application shuts down), the server receives both Shutdown and Exit notifications, and once they’re handled and the server actually shuts down we’ll be left with a clean exit every time.
Logging is implemented on both client and server sides, and while debugging the startup and initialization was a bit painful (can’t start the server from Visual Studio, and can’t hook up the debugger quickly enough to attach in time to see what’s going on), now that it’s done the server process can be attached after it starts, so we can hit breakpoints in the server code.
Net7
Perhaps the biggest achievement is that RD3 is now building with .net 7.0, save for a specific library that has to target Framework 4.8.1 because of its use of a number of COM-marshaling methods that don’t (yet?) exist in .net core: that’s the parts dealing with unmanaged memory and pointer magic, that allow RD2 to run unit tests, among other things.
Because everything else is under .net7, Rubberduck gets to leverage all the amazing enhancements that have been brought to the C# language and development platform in the past, uh, decade or so. RD3 will likely release under .net8, which has long-term support from Microsoft.
There’s a catch though: this means RD3 will not be able to run on old, officially unsupported versions of Windows – we’re forfeiting them, in favor of being able to leverage the many enhancements being made to the .net platform. At this stage it’s still unclear exactly what this means for VB6 support: for now the focus is integrating with the VBIDE in VBA, but nothing says VB6 support is being ditched – it was just simpler to exclude that one RD library from the solution for now.
Settings
One of the first pieces of Rubberduck written around this time back in 2014 – the settings I/O and modeling – has officially been axed at long last. Since forever, Rubberduck settings have been serialized to an XML configuration file. In RD3 that’s changing to JSON and much simplified abstractions. In RD2 the default settings live in an XML-encoded “Settings.settings” file that’s a pure nightmare to maintain; in RD3 defaults are moving back into the code itself (I know, it’s data, not code per se), with each serializable struct implementing a generic IDefaultSettingsProvider interface that mandates the presence of a “Default” member that returns a static instance of that settings struct (e.g. LanguageServerSettings.Default, returns a LanguageServerSettings instance with the hard-coded default values.
JSON settings is how pretty much everyone else does it, and there’s a reason for that: the format is much easier to read and manually edit. Plus we already have JSON involved with the RPC messages between client and server. XML was originally adopted because that was the format for Visual Studio’s own settings and configuration under .net Framework 4.x.. and today it’s JSON everywhere.
Rubberduck Editor
Last spring the prototype editor was being integrated into the VBE using essentially the same mechanics used in RD2 for the dockable toolwindows, just undocked and basically turned into just another VBIDE document window.
With the project now under .net7, it turns out we can now have actual WPF/XAML windows in Rubberduck, so there is no more need to implement the entire UI as user controls that are embedded inside a WinForms user control that gets injected into a native toolwindow.
The RD3 editor will let go of most of the native VBIDE integration, and live in a separate window – very much like the Power Query Editor in Excel. The only native UI components in RD3 are the Rubberduck menu items, which have been boiled down to just “Show Editor” and “About” commands, both of which will now bring up a fully WPF UI, rather than a WPF UI embedded in a WinForms dialog: the Rubberduck Editor will be its own application, and we’ll have full control over everything that happens inside that editor.
The downside (if it is one), is that we have to implement basic commands such as Copy and Paste, as well as toolwindows we take for granted, like Properties and Object Browser.
At this stage the editor shell is able to display tab documents bound to a ViewModel; tabs can be moved around, torn from the main window and dragged to another monitor, or docked inside the editor shell. I’m now working on figuring out how the toolwindows are going to work; I’d like something similar to Visual Studio, but the Dragablz library would need to be forked and updated with such capabilities… the “toolwindows” aren’t docking and don’t work in a way that would make sense in a code editor.
Workflow
This does impact the VBA dev workflow: in RD2 the single source of truth was the VBE. In RD3 that’s no longer the case, since the VBE isn’t going to contain the code that’s being edited. The single source of truth in RD3 is going to be moving to the Rubberduck Editor, and the editor will be working off code files exported to file system folders, dubbed “workspace folders”.
When the Debug/Run command is executed, the RDE will save all modified documents to the workspace, synchronize the host VBA project components to mirror it, and then the VBE takes over from that point on (RDE window will minimize itself) to compile and actually run/debug the project.
The host VBA project can also be synchronized any time you want, using the File/Synchronize command – and the editor will run a FileSystemWatcher on workspace folders, so it will detect any external changes/additions/deletions, and immediately notify the language server. If external changes are detected on a file that is opened in the editor, it will prompt to either reload the document, or keep the editor version if it has unsaved changes (thus discarding the external changes).
In RD2 you had to manually tell Rubberduck about changes occurring in the VBE, because automatically parsing on idle involved low-level keyboard hooks and since these hooks were already involved in auto completion and hotkeys, it was deemed too invasive, and ran against the basic premise of the parser, which is that we’re operating with legal, compilable code.
This all changes dramatically in RD3. Because the editor is fully managed, nothing happens in it without the language server receiving requests and notifications. Content changes synchronize in real-time, the editor receives responses with completion lists, syntax errors to highlight (squiggles!), or edits (e.g. auto-formatting etc.) made server-side that the editor immediately carries into the code pane as you type – exactly like how Visual Studio and VSCode and any other modern-day code editor that works with a language server.
The server works asynchronously and out of process, so long-running tasks can send progress notifications, and even partial responses – for example a completion list might only include names to render the list in the client, and the associated tooltips and commands might be sent a few milliseconds later.
Debugging
As was mentioned before, the one thing the RDE cannot do, is attach as a debugger to your running VBA code. When you debug, the RDE will minimize itself and leave the VBE in charge. Edit-and-continue poses a particular challenge: after a debug session, the RDE doesn’t know if anything was modified in the VBE, and its file system watchers cannot help because code doesn’t just magically export itself back to the workspace folders – so here’s what we’re looking at:
When a debug session is launched from the RDE, code gets synchronized into the VBE before it is compiled and executed;
If the RDE is re-focused and the VBE is back into edit mode (i.e. debug session has ended), the entire workspace gets refreshed with a new export from the VBE;
If the RDE is re-focused during a debug session, document tabs will be read-only and the status bar will indicate why;
If the host application crashes, or the debug session does not end with the RDE being brought back before the host application shuts down, then the single source of truth resides safely in the host document and the workspace will synchronize next time the RDE loads this project;
Any edits made to the exported workspace files during a debug session would be overwritten and lost when the session ends and the RDE is re-focused, unless source control is involved and the changes were committed – in which case the modifications can then be recovered from source control.
Breakpoints cannot be set programmatically either, so the RDE will likely not support them. Bookmarks have a similar problem, in that the VBIDE API doesn’t really let us manipulate them, however the RDE can very well have its own bookmarks system. Debugger toolwindows (immediate, locals, call stack, etc.) are also not going to be present in the Rubberduck Editor, since they’d all be useless without a debugger attached.
User Interface
Some parts of RD2 XAML markup may survive, but really the intent is to make the RDE have a consistent, pleasing, modern, intuitive, and functional user interface for all of its functionalities. Because we’re no longer confined to a WinForms/native host, key/command bindings (hotkeys) will no longer require any kind of bug-prone hooking; focus should behave much more naturally as well, and drag-and-drop is going to be a breeze with the Dragablz library. RD3 basically entails crafting an entire IDE UI from scratch, starting with the editor shell.
The RDE window features a complete menu bar (largely inspired from Visual Studio’s), an actual status bar, and the client area consists of a Dockablz layout panel hosting a Dragablz document tab container.
Some more tinkering is still needed around toolwindows, because what we get out of the box with Dragablz is not going to work for our purposes. Perhaps there’s a way to split the left and right docking areas in two so there’s a distinct drop location for toolwindows that displays them with the tabs at the bottom, but for now there’s no such thing and toolwindows are essentially just another type of document tab.
Another thing that will need attention ideally before the entire UI is done, is theming: indeed it would be sad to make our own editor from scratch without supporting light, dark, and custom themes and syntax highlighting!
Server Side
The LSP server is in place, handling server lifecycle requests and notifications. The next step is to beef up the initialization to send the server information about the project(s) loaded in the VBE, including whether it’s an unsaved new blank project or an existing one hosted in a saved document, and a URI for each library reference so the server can load them and extract all the types and their respective members.
Then we’ll need to setup the actual workspace folders and parse any code files in them – and when we’re done doing that we can send the semantic tokens to the editor to perform syntax highlighting and folding ranges, all while the server starts running diagnostics/inspections, prioritizing the documents that are opened in the editor. The client-side code for this was written in the prototyping stage, so it’s not complete but exactly how that’s going to work is already all figured out.
2023.Q4
The last quarter of 2023 is likely to see lots of progress on all fronts: with LSP in place and a working but bare-bones editor, I can see myself focusing on UI work mostly, while other contributors hop on and work on server-side processing – much of which will have to be ported from the RD2 code base and reworked to fit the new paradigms.
There is a lot of work ahead, but with the client/server communications happening, things that have been on our minds for years, are about to get very real.
I’m pleased to announce that Rubberduck release version 2.5.2 has achieved over 32 thousand total downloads this month, overflowing a VBA Integer data type! Big numbers are fun and all, but the time has come to reset the counters and officially release the next version.
Those of you that have been keeping up with the many pre-release builds for the past two years will not have too many surprises here, but for the vast majority of you this will be a welcome upgrade with the combined efforts of our contributors over the past 20 months or so. That’s two Hacktoberfests and over 700 commits from 180 pull requests!
See rubberduckvba.com/features for more information about Rubberduck features.
What’s New?
This release brings an awesome new peek definition navigation command (pre-released in 2021!), which lets you view source code that’s anywhere else in the project, without leaving where you’re at.
The Fakes API has been seriously enhanced with more than a dozen new standard library function overrides, as discussed in details in a previous article.
The version check feature is no longer sending HTTP requests to legacy routes on the website (although the website still supports them, so the feature still works in older Rubberduck installs). Instead, an HTTPS request is sent to the public API behind the website – the result is a more reliable feature that now receives much more information than just a version number. It wouldn’t be surprising to see a future iteration show additional information about the latest tag/release, such as the number of downloads, and the installer executable asset URL, for example.
A Rubberduck release wouldn’t be a Rubberduck release without at least a handful of new inspections! 6 new inspections are coming this time around:
IIf side-effects flags uses of the IIf function where arguments are potentially side-effecting.
Public control field access flags code that accesses form controls from outside the form, recommending a more encapsulated approach.
Public Enum in Worksheet module warns about Enum types declared in a Worksheet document module, which can easily result in compilation errors when the worksheet is later copied.
Suspicious predeclared instance access warns about accesses to a form’s predeclared instance made in that form’s code-behind module; depending on how the form is used, such code may not work as intended.
UDT Member not usedfinds UDT members that are declared without being referenced anywhere.
The Extract Methodrefactoring is making a long-awaited comeback, 5 whole years after the old 2.0 implementation was deemed irreparably broken. It has a number of limitations, for now the selection to extract cannot contain any of the following:
GoTo statements
GoSub...Return statements
Conditionally-compiled statements
This obviously isn’t an exhaustive list of everything that happened in the last two years, but it’s a good summary of the new stuff.
What’s next?
This release is the last one planned to start with a 2; work has started on Rubberduck 3.0, a major overhaul of everything we’ve built so far. Rubberduck is being split into client/server processes, storage is moving out-of-process, and the entire user interface is being remade to support everything that’s coming in v3.
Because a massive number of breaking changes need to happen, RD3 is being developed in a separate repository; you’ll find it under the rubberduck-vba organization on GitHub, and that’s where the bulk of development efforts are going to be directed at in the coming months.
Website
The new revamped website is live now; still has a couple of annoying issues (search results page links don’t work, for one), but overall I’m very happy with how it turned out!
Swag Shop
If you’re following Rubberduck on social media, you know I’ve opened a swag shop where you can get Rubberduck-branded mugs, pens, stickers, t-shirts, and more; these past couple of weeks I’ve been building an assortment of various products at various price points for various budgets. Shipping remains a challenge (it’s expensive!), but Ko-fi doesn’t take a cut on shop sales (or donations), which makes it a better deal for a shop with uncertain sales, compared to say Amazon, where shipping is less of a challenge but the monthly fees are prohibitive for a small-volume shop.
There’s now a rather decent offering and quite a lot of inventory; eventually I’ll get more stuff made (hats, hoodies maybe), and will replenish whatever runs out, but my attention will be mostly dedicated to Rubberduck3 development now.
Rubberduck 2.x has been an amazing adventure and a tremendous learning experience – I’m primed and looking forward to all the new challenges porting 2.x to RD3 will bring!
I’ve embarked on a journey to take Rubberduck to the next major version, making it the add-in we’ve always wanted to build. These monthly updates provide a sneak peek at what’s coming, and how it’s coming to be.
Quick catch-up
Rubberduck 3.0 will run a LSP server process in the background
A separate process will host a local SQLite database
Telemetry will be opt-in, fully configurable, and transparent
Several quite important low-level changes since last time: we’re now looking at named pipes rather than sockets for the JSON-RPC communications between the editor and the language server, and I’m now using Microsoft’s StreamJsonRpc library for this. Named pipes are inherently local, so they’re less of a concern than sockets, and they don’t seem to trip up Windows Defender, so we’ll take it!
I spent the better part of last month tidying up and documenting the code off the language server protocol (LSP) specifications, moving things around and splitting up responsibilities, writing abstractions that will be shared by all server processes: LSP and SQLite, but also a separate/dedicated server process for telemetry, so even constant writes couldn’t interfere much with LSP server activities, or with the add-in client.
At the time of this writing, I’m still somewhat struggling with the RPC communications, but that won’t remain stuck for too long – the plan is to merge a rather large structural PR and the whole RPC infra by the end of this week.
The Rubberduck.Server.LocalDb console at startup. This process will normally run in the background, hidden.
I’ve taken a number of important decisions about the project in the last few weeks.
GitHub Repository Issues
Since the project’s beginning, Rubberduck was pretty much ad-hoc development. I remember in the first few days after creating the GitHub repository, going on an issue-creation spree to write down everything I could dream the thing could do. A lot of it was implemented, but the oldest open issues in the repository are from 2014, 2015:
2,857 issues closed is quite something. 958 open feels daunting though. Using issues as a backlog might not have been the best of ideas…
I’m not going through nearly a thousand issues to sort out what’s already implemented/fixed, what’s unrealistic after all, what’s a good idea that got buried under a million others, etc. Implementing LSP isn’t magically going to clean this up, and when 3.0 releases we’re not going to be maintaining two distinct, massive code bases: one of them isn’t going to make it, and it’s sadly going to have to be the one with 1.7K stars and 284 forks and 97 watchers. I can hardly express how I feel about these numbers, let alone those:
As of 2023/02/14, release tag 2.5.2.1 (build 2.5.2.5906) has been downloaded 27,320 times… that’s crazy!
The repository isn’t going anywhere though – it’s just that at some point in the [somewhat-near] future, it’s going to be made read-only and essentially archived, and the Rubberduck3 repository will become Rubberduck’s new home on GitHub (you’ll still find it under the rubberduck-vba organization).
Rubberduck is still accepting pull requests for v2.x and will continue to do so until further notice.
Methodology Upgrade
If building Rubberduck up to v2.5 was pretty much ad-hoc (and that’s fine!), I don’t think the same strategy would work with v3.0; we can’t just go and create a thousand issues to churn through, or pick a feature to implement because it looks like it’s going to be fun to do. Rubberduck 3.0 is still an embryo at this point, and while all the DNA is there and we know exactly (at least in large fuzzy outlines) what we want this add-in to do, this time things need to happen in order, for technical reasons mostly, but also for project management.
By adopting a different development methodology, we’re going to better control the backlog and project progression. We can better track what’s in progress and determine what the next logical steps should be.
Instead of making a ton of issues, we’ll be drafting them, sizing them, prioritizing them, refining them until they’re small enough to be realistically achievable within a week or two of part-time contributions. Work items will now have a life cycle like this:
New items/ideas not yet fleshed out, not yet planned, and/or not yet prioritized.
Backlog for work items being documented.
Ready for documented work items that are ready to be worked on; items are assigned a sprint (not necessarily the next one), and convert into issues at this stage.
In Progress is work in progress; a branch is created for resolving that issue.
In Review is work items ready to be peer reviewed; a pull request is opened at that stage.
Done is when the work is merged into dev/next.
Delivered status is set when the work is merged into main.
Items/issues will be assigned a priority level:
Urgent is the highest priority level, for things that should be worked on before anything else.
High is for work that’s directly aligned with the objectives of the sprint it’s in.
Medium priority work could be delayed a sprint or two.
Low priority work doesn’t need to be in the current sprint, but would be nice to deliver anyway.
The priority level of any given issue likely evolves over time, particularly the lower-level ones.
In addition to status and priority, each draft issue / work item gets sized. Again this is meant to evolve over time: issues should become smaller over time as they are refined and documented and broken down into smaller tasks.
X-Large items represent a large development that should be broken down into smaller tasks.
Large items represent a significant development effort that can realistically be completed within a sprint by a single developer.
Medium items represent perhaps up to 2-3 days of effort.
Small items represent small tasks that can be completed in a few hours.
Tiny items represent tasks that should only take a few minutes: fixing a typo, adding a column to a database view or table, a configuration tweak, etc.
As of this writing, Sprint 1 is in its second half, and I’m still working on the RPC infrastructure:
“Project Cucumber” – it just had to be named that.
There’s a bit of history around the cucumber thing, and it involves two major contributors we lost and think about fondly all the time.
Comintern simply disappeared one day after a brief return, after a year under terms that essentially prevented him from working on open-source projects and hanging out in a public chat. We’re all hoping he’s all right and will eventually pop back.We lost our beloved ThunderFrame to a fierce cancer in late 2018. Rest in peace, my friend. I got the Ctrl+Alt+Delete cushion covers you wanted me to have.
Discord Server
Rubberduck’s dev chat was always in a Stack Exchange room under the Code Review site. In fact it’s just a Code Review chat room we ended up [ab]using for this purpose. Back in 2014 I was very active on CR, and as a moderator on that site in 2015-2018 it made a lot of sense to keep it there.
But with 2-week sprints and a living backlog, we’re going to need more than SE chat to pull this off, and this is where Discord shines.
The general chat is fun, but a nice thing about Discord is that you can schedule events, like a public Sprint Review presentation every two weeks, followed by a Sprint Planning conversation among developers.
I’ll be hosting these events regularly, whether there’s an audience or not, whether other contributors are present or not.
Sprint Review
At each end of a sprint, we’re going to be going over what was done in the previous two weeks, and developers will present/demo their work. Since I’m doing sprint 1 by myself the first review will be me going over the solution structure and explaining the mechanisms and abstractions involved at a high level; reviews for sprint 2 and onward will likely involve more contributors, and things will get more and more exciting to present every time.
Sprint Planning
After the review concludes, developers convene to plan a realistically deliverable workload for the upcoming sprint. If we overshoot and under-deliver, we can always adjust the next sprint. If we over-deliver, we can always pull work items from upcoming sprints into the current one. So this conversation is about the work itself, whether there’s enough information in an issue for anyone at the table (or not!) to pick up and complete that task within two weeks, and whether the backlog is healthy or falling behind; if it’s falling behind, we take the time to talk about what needs to happen and outline work items to be drafted and refined during the sprint (I’ll be doing that backlog maintenance).
So yeah, Rubberduck3 is starting to feel very much like it’s just about to officially kick off, and Rubberduck as a project is entering a whole new phase, in continuous delivery mode.