
I’ve embarked on a journey to take Rubberduck to the next major version, making it the add-in we’ve always wanted to build. These monthly updates provide a sneak peek at what’s coming, and how it’s coming to be.
Quick catch-up
- Rubberduck 3.0 will run a LSP server process in the background
- A separate process will host a local SQLite database
- Telemetry will be opt-in, fully configurable, and transparent
- January update
Several quite important low-level changes since last time: we’re now looking at named pipes rather than sockets for the JSON-RPC communications between the editor and the language server, and I’m now using Microsoft’s StreamJsonRpc library for this. Named pipes are inherently local, so they’re less of a concern than sockets, and they don’t seem to trip up Windows Defender, so we’ll take it!
I spent the better part of last month tidying up and documenting the code off the language server protocol (LSP) specifications, moving things around and splitting up responsibilities, writing abstractions that will be shared by all server processes: LSP and SQLite, but also a separate/dedicated server process for telemetry, so even constant writes couldn’t interfere much with LSP server activities, or with the add-in client.
At the time of this writing, I’m still somewhat struggling with the RPC communications, but that won’t remain stuck for too long – the plan is to merge a rather large structural PR and the whole RPC infra by the end of this week.

I’ve taken a number of important decisions about the project in the last few weeks.
GitHub Repository Issues
Since the project’s beginning, Rubberduck was pretty much ad-hoc development. I remember in the first few days after creating the GitHub repository, going on an issue-creation spree to write down everything I could dream the thing could do. A lot of it was implemented, but the oldest open issues in the repository are from 2014, 2015:
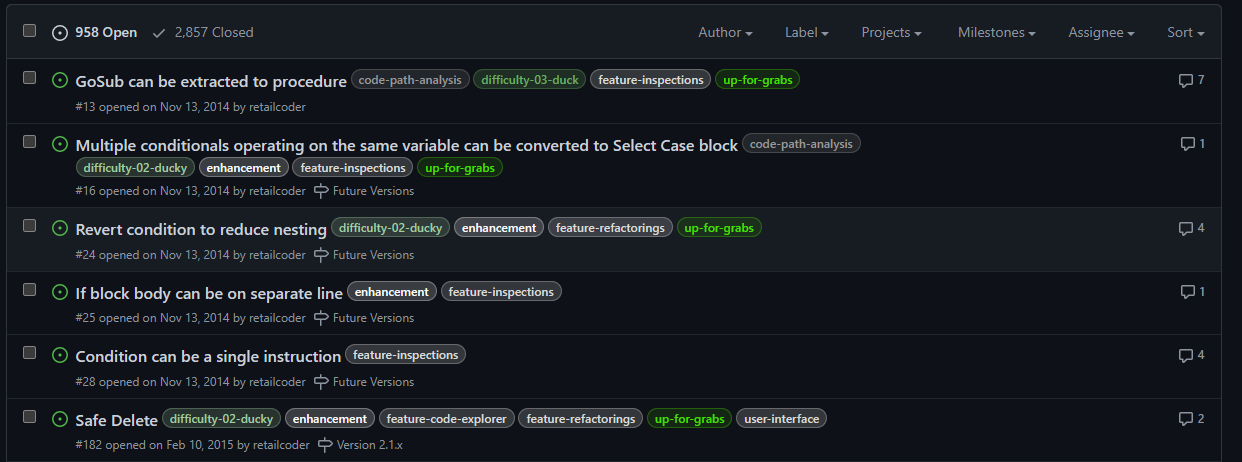
I’m not going through nearly a thousand issues to sort out what’s already implemented/fixed, what’s unrealistic after all, what’s a good idea that got buried under a million others, etc. Implementing LSP isn’t magically going to clean this up, and when 3.0 releases we’re not going to be maintaining two distinct, massive code bases: one of them isn’t going to make it, and it’s sadly going to have to be the one with 1.7K stars and 284 forks and 97 watchers. I can hardly express how I feel about these numbers, let alone those:

The repository isn’t going anywhere though – it’s just that at some point in the [somewhat-near] future, it’s going to be made read-only and essentially archived, and the Rubberduck3 repository will become Rubberduck’s new home on GitHub (you’ll still find it under the rubberduck-vba organization).
Rubberduck is still accepting pull requests for v2.x and will continue to do so until further notice.
Methodology Upgrade
If building Rubberduck up to v2.5 was pretty much ad-hoc (and that’s fine!), I don’t think the same strategy would work with v3.0; we can’t just go and create a thousand issues to churn through, or pick a feature to implement because it looks like it’s going to be fun to do. Rubberduck 3.0 is still an embryo at this point, and while all the DNA is there and we know exactly (at least in large fuzzy outlines) what we want this add-in to do, this time things need to happen in order, for technical reasons mostly, but also for project management.
By adopting a different development methodology, we’re going to better control the backlog and project progression. We can better track what’s in progress and determine what the next logical steps should be.
Instead of making a ton of issues, we’ll be drafting them, sizing them, prioritizing them, refining them until they’re small enough to be realistically achievable within a week or two of part-time contributions. Work items will now have a life cycle like this:
- New items/ideas not yet fleshed out, not yet planned, and/or not yet prioritized.
- Backlog for work items being documented.
- Ready for documented work items that are ready to be worked on; items are assigned a sprint (not necessarily the next one), and convert into issues at this stage.
- In Progress is work in progress; a branch is created for resolving that issue.
- In Review is work items ready to be peer reviewed; a pull request is opened at that stage.
- Done is when the work is merged into dev/next.
- Delivered status is set when the work is merged into main.
Items/issues will be assigned a priority level:
- Urgent is the highest priority level, for things that should be worked on before anything else.
- High is for work that’s directly aligned with the objectives of the sprint it’s in.
- Medium priority work could be delayed a sprint or two.
- Low priority work doesn’t need to be in the current sprint, but would be nice to deliver anyway.
The priority level of any given issue likely evolves over time, particularly the lower-level ones.
In addition to status and priority, each draft issue / work item gets sized. Again this is meant to evolve over time: issues should become smaller over time as they are refined and documented and broken down into smaller tasks.
- X-Large items represent a large development that should be broken down into smaller tasks.
- Large items represent a significant development effort that can realistically be completed within a sprint by a single developer.
- Medium items represent perhaps up to 2-3 days of effort.
- Small items represent small tasks that can be completed in a few hours.
- Tiny items represent tasks that should only take a few minutes: fixing a typo, adding a column to a database view or table, a configuration tweak, etc.
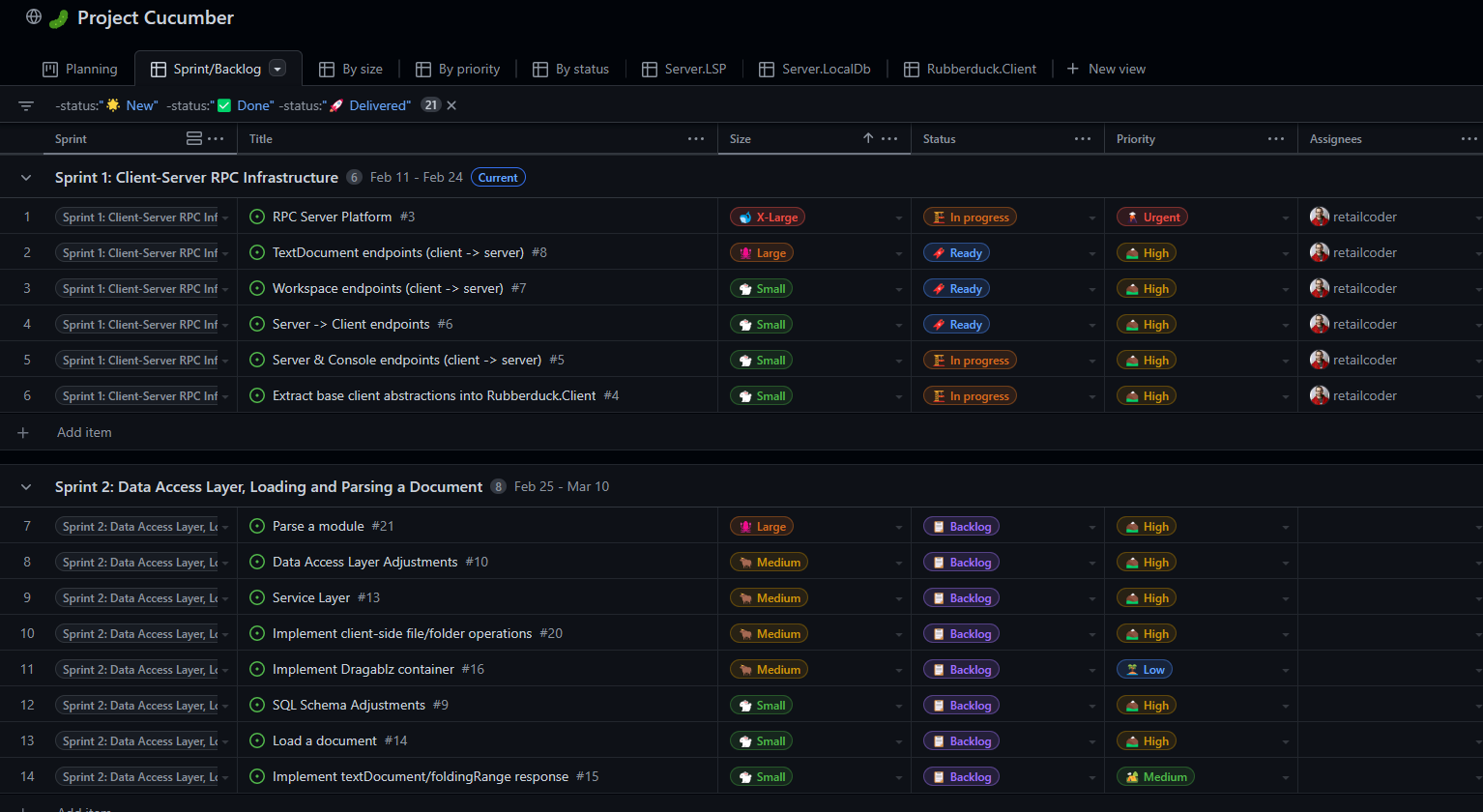
As of this writing, Sprint 1 is in its second half, and I’m still working on the RPC infrastructure:
There’s a bit of history around the cucumber thing, and it involves two major contributors we lost and think about fondly all the time.


Discord Server
Rubberduck’s dev chat was always in a Stack Exchange room under the Code Review site. In fact it’s just a Code Review chat room we ended up [ab]using for this purpose. Back in 2014 I was very active on CR, and as a moderator on that site in 2015-2018 it made a lot of sense to keep it there.
But with 2-week sprints and a living backlog, we’re going to need more than SE chat to pull this off, and this is where Discord shines.

I’ll be hosting these events regularly, whether there’s an audience or not, whether other contributors are present or not.
Sprint Review
At each end of a sprint, we’re going to be going over what was done in the previous two weeks, and developers will present/demo their work. Since I’m doing sprint 1 by myself the first review will be me going over the solution structure and explaining the mechanisms and abstractions involved at a high level; reviews for sprint 2 and onward will likely involve more contributors, and things will get more and more exciting to present every time.
Sprint Planning
After the review concludes, developers convene to plan a realistically deliverable workload for the upcoming sprint. If we overshoot and under-deliver, we can always adjust the next sprint. If we over-deliver, we can always pull work items from upcoming sprints into the current one. So this conversation is about the work itself, whether there’s enough information in an issue for anyone at the table (or not!) to pick up and complete that task within two weeks, and whether the backlog is healthy or falling behind; if it’s falling behind, we take the time to talk about what needs to happen and outline work items to be drafted and refined during the sprint (I’ll be doing that backlog maintenance).
So yeah, Rubberduck3 is starting to feel very much like it’s just about to officially kick off, and Rubberduck as a project is entering a whole new phase, in continuous delivery mode.
Join us on Discord to keep up! (<~ feel free to share that link!)

Will Rubberduck work with windows on Arm (don’t create an issue for it 😝 if it doesn’t) because last time I checked it would not install 2.x on windows on arm yielding it was only supported to work on x64 and x86.
Don’t know if you are still doing this in your free time? But I would suggest adding a support option of some sort to be able to work on it more sustainable or even include some other people.
Nice to read the post good luck 🤞
LikeLiked by 1 person
Thanks! At this time the RD3 solution is targeting Framework 4.8, but there is work under way to get everything under .net 6 (LTS), which probably means inevitably dropping support for older Windows and out-of-support Office versions.
At the moment however, deployment and installer concerns are pretty far down the road still, but targeting .net-current means, in theory, that everything is as cross-platform as . net-current is.
We’re all doing this in our free time 😉
I definitely don’t intend to make RD3 all by myself! That’s exactly what the outlined methodology unlocks: true coordinated and productive teamwork. At the same time, as much as I want other people to join and contribute, I can’t and won’t impose any workload on anyone, that’s why we’re going with small, 2-week iterations: that way contributors can much more easily see where the project is at a glance, and pick up and deliver any task at any time – the planning is fluid and will be constantly evolving, as will the dev team’s composition: I’m hoping that a tightly maintained, manageable backlog that doesn’t scare away new contributors, and a development process that makes every (or most) task achievable by any contributor, is a step in the right direction.
The development process should work and scale as the size of the dev team evolves.
LikeLike
I code in Excel VBA. How does this relate? When will this help me and how?
Thank you.
Kevin Hankins, Data Your Way Highland Springs, VA 804-244-2696 datascientist7@gmail.com
LikeLike
Hi Kevin, I maintain an open-source project that’s specifically made for people like you, who code in VBA.
I could be wrong, but discussing software development methodologies might be something beneficial to anyone writing code for a living, regardless of the language or team size. Also I could be wrong again, but I like to think readers enjoy getting project status updates and know that Rubberduck is still very much alive despite not having seen an “official” release in nearly two years. Not that I care much about likes, but the January update post received more likes than any other article on this blog, in just a few days. For me that’s a strong signal that talking about how RD3 is coming along is a good idea, and starting a Discord server for the project, to me, sounds like something I should be writing about on the project’s blog.
As I wrote before, I pretty much burned out producing regular VBA content and stressing about MVP renewals and whatnot – as my attention is shifting to making v3 happen, I have less time and energy to give VBA content, and my mind is focused on RD3 and Stack Overflow is a broken record of neverending duplicates, so VBA article ideas aren’t exactly raining on me at the moment, but I’ll certainly be writing VBA articles as the RD3 project picks up a pace and ideas happen.
Is there a particular topic you would like to be discussed?
LikeLike
Can I use this now to help code in Excel VBA? If so, how? Thank you.
LikeLike
WordPress isn’t making this very clear, but this article is actually posted under “announcement” and “rubberduck-source” categories. Cheers!
LikeLike
Thanks Mat for all your hard work. As a seasoned VBA developer, rubberduck is a much-needed extension.
Thank you man
LikeLiked by 1 person