In Rubberduck 1.x, we processed each module in each project sequentially. Rubberduck 2.0 will change that and have the parsing happen in parallel, asynchronously. After parsing all modules, we need to resolve identifier references – that isn’t changing in 2.0. The 2.0 parser is a great improvement over the 1.x, but the high-level strategy remains the same.
What’s happening under the hood?
The hard work is really being done by ANTLR here. We have an ANTLR grammar that defines lexer and parser rules that, together, define what text input is legal and what input isn’t. Of course that grammar isn’t perfect, and when the parser rules mismatch the actual VBA language rules, the result is code that the VBE can compile, but that Rubberduck can’t parse. A good example of that is the set of parser rules for #If/#EndIf precompiler directives/blocks:
macroIfThenElseStmt : macroIfBlockStmt macroElseIfBlockStmt* macroElseBlockStmt? MACRO_END_IF; macroIfBlockStmt : MACRO_IF WS? ifConditionStmt WS THEN NEWLINE+ (moduleBody NEWLINE+)? ; macroElseIfBlockStmt : MACRO_ELSEIF WS? ifConditionStmt WS THEN NEWLINE+ (moduleBody NEWLINE+)? ; macroElseBlockStmt : MACRO_ELSE NEWLINE+ (moduleBody NEWLINE+)? ;
This definition is flawed – the moduleBody rule only allows functions, procedures and property definitions; therefore, any #If block in the declarations section of a module will trip the parser and fire a parser error, even though the VBE compiles it perfectly fine.
Not only that, but a limitation of the grammar makes it so that whatever we do, we’ll never be able to parse the [horrible, awfully evil] below code correctly, because that #If block is interfering with another parser rule:
#If DEBUG Then
Sub DoSomething()
#Else
Sub DoSomethingElse()
#End If
'...
End SubAdditionally, we’ll never be able to resolve the below code correctly, because MyMember exists twice in the same scope:
Private Type MyType
#If DEBUG Then
MyMember As Long
#Else
MyMember As Integer
#End If
End Type
So, during the parsing phase, we use ANTLR to generate a parse tree for every module in every project in the VBE; one problem, is that a parse tree only contains the code of one module, and despite there being grammar rules to define what’s a variable and what’s a procedure, nothing in the grammar defines context, so there’s no way the parse tree alone can know whether “foo =42” means you’re assigning the return value of a function called “foo”, or if you’re assigning 42 to a local variable, or to a global one; the parse trees know nothing of VBA’s scoping rules. And since there’s a parse tree per module, there’s no way “foo” in parse tree A could be known to refer to the “foo” declared in parse tree B.
That’s why we need to further process these parse trees.
First pass: find all declarations
So we walk the parse trees – each one of them. We locate all declarations; everything that has a name that can be referenced in VBA code is a declaration. Look at the DeclarationType enum: no less than 24 things are considered a “declaration” – even line labels.
In Rubberduck 1.x, we traversed each parse tree one after the other; in 2.x, when we need to parse everything in the VBE, we traverse each parse tree in parallel – which may or may not mean that two or more parse trees are being traversed at the same time, depending on your hardware and other things.
The longer a code module is, the longer it takes to process it.
One thing to note, is that while we’re walking the parse trees and capturing “Dim” statements that declare variables, there’s no way we can capture a variable that’s used but undeclared at that point – without Option Explicit set, an undeclared variable simply goes completely under the radar… and there’s nothing we can do about it, since there’s, well, no declaration for it.
The other thing to note, is that if a single parse tree is in an error state, everything falls apart because that parse tree is missing declarations, and identifier usages – hence, we’re disabling all Rubberduck features that require a Ready state, whenever any module can’t be parsed.
Second pass: resolve identifier usages
Once we know what’s what, what’s declared where and how, we have the context that the grammar alone couldn’t define – we know that there’s a “foo” variable scoped locally to a function called “GetFoo”, on line 42 of “Module1”. That’s great, but still not good enough for our needs. We also need to know that function “GetFoo” is called on line 12 of “Module2”, and whether and where “foo” is assigned a value.
The only way to do this, is to walk the parse trees again – this time tracking what scope we’re in as we walk down the module, and every time we encounter an identifier reference, we need to figure out exactly what declaration we’re looking at.
And that’s not exactly easy. VBA allows mind-blowingly ambiguous code to compile just fine, so “foo” can very well be referring to a half-dozen potential declarations: which one it’s actually referring to depends on the current scope, and whether our implementation of VBA’s scoping rules is correct:
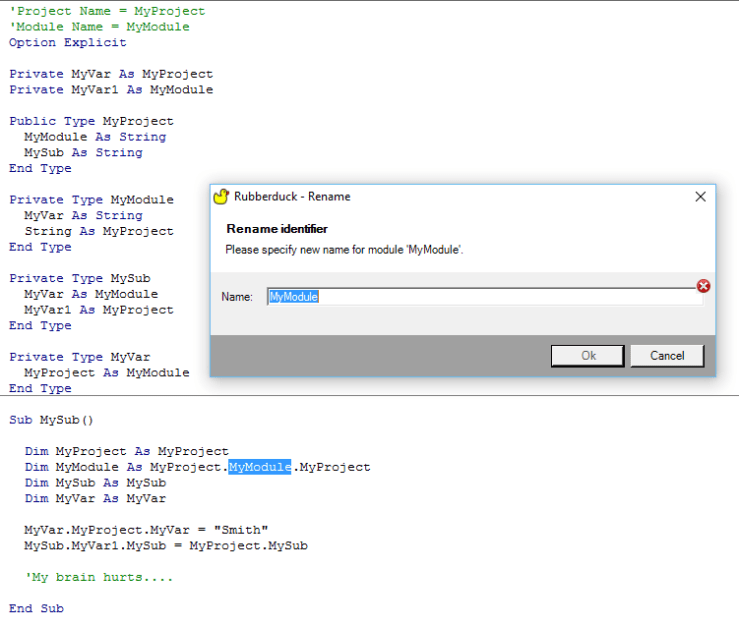
For a vast majority of cases, we’re doing good. And the 2.0 resolver is, so far, fixing a good number of issues too, so we’re getting even better… but it’s still not perfect.
What happens if we don’t resolve “foo” correctly? Bugs! You right-click “foo” and select “find all references”, and you get surprises. And then you refactor/rename it, and you end up breaking your code instead of improving it. Not quite what we intend to happen.
Why re-resolve everything everytime?
All of the above processing doesn’t happen all the time. In Rubberduck 1.x, we cached parse trees and used a hash of the content of each module, to determine whether a module had been modified since the last parse. In Rubberduck 2.x, we want to have a keyhook to capture modifications to a module as it’s happening, and start reparsing that module in the background while you’re typing – so when you’re ready to use one of Rubberduck’s features, the changes have been processed already.
That leaves a little gap though: if you’re cutting/pasting code with your mouse, or if another add-in modifies the code, the keyhook alone won’t pick up the changes, so 2.0 will still need the content hash, to avoid re-parsing modules that didn’t change, and to re-parse modules that we didn’t know actually changed.
The reason we need to parse an entire module (versus, for example, just the procedure that was just modified), is because the parse tree is made of tokens, and tokens retain their position… in the parse tree: unless the parse tree contains the entire module, we don’t know where in the module a token is located. And that’s crucial information.
That covers the parser. But what about the resolver?
We still need to re-walk every parse tree and resolve every identifier usage, every time a single module’s been parsed. The resolver task needs to start when all modules have completed parsing, and to cancel when any module starts a re-parse. If we could somehow examine a diff of the pre and post parse trees, and determine exactly what declarations and what identifier references have been added or removed, perhaps we wouldn’t need to do the whole thing.
But because we can’t know if the modified code is referring to things declared in another module, we need to make sure everything is kept in sync, …and the cost of this is to walk the parse trees and re-resolve everything again.
In Rubberduck 1.x this was a UI-blocking operation, and we displayed a little “progress” dialog that showed what module was being walked.
In Rubberduck 2.0 this will happen in the background, and parse trees will be walked in parallel, so we won’t be able to display that little “progress” dialog, because at any given time more than one module is possible being walked.
Instead, we’ll make a little UI that will display the state of each module, but that UI will only show up when you click the parser state label on the Rubberduck CommandBar, a new toolbar we’re adding to the VBE to compensate for the lack of a status bar in the IDE.
In Rubberduck 3.0 we hope to be able to restructure things in such a way that we’ll be able to minimize the amount of parse tree walking, and hopefully resolve identifier references in a smarter way… but 3.0 is a long way down the road; Rubberduck 2.0 is coming along nicely, but we still can’t commit to a release date at this point, unfortunately.
Stay tuned!