The v3 full rewrite failed, obviously. The project was simply too ambitious for the limited capacity of an open-source weekend project.
Rubberduck is at a crossroads: either there’s a way forward, or sooner or later it’s a way to the graveyard.
You thought this was going to be about Rubberduck going “on indefinite pause”, didn’t you? If you haven’t seen the recent movement around the project’s website and GitHub organization, I wouldn’t blame you for thinking so, but…
I can’t let that happen to Rubberduck. This project means too much to me, to just let it die like this.
Not after all the blood, guts, and sweat that went into it.
It’s 2026. VBA has been “dead” for what, 20 years now? It’ll be “dead” for another 15 and Microsoft will still do nothing about modernizing VBA: they’ve essentially left that ground to the community – and that’s us.
And I’m perfectly fine with that.
I have no idea how big or small Rubberduck’s user base is; all I have is rough estimates. I know the total number of installer downloads for any given release tag, that’s all. I never collected any data from our users, because an OSS project that can’t sign their code shouldn’t be doing that, plus where’s the infra and who’s paying for it? I’ve poured quite a lot of my own money into this over the course of the past decade or so, and Enterprise-approvable, certified/signed code is crazy expensive and simply wasn’t going to happen under a pure open-source GPLv3 model at my sole expense.
Meanwhile we’ve built a reputation for ourselves and are now positioned as the reference for professional-level VBA code, and Microsoft’s own flagship AI tool – Copilot – spontaneously names Rubberduck as the best tool in the ecosystem in 2026 and validates our unit testing features as a unit testing framework that is comparable to industry-standard NUnit/JUnit. To me it says something about how deep the actual reach goes, and how dead VBA actually still isn’t.
“the best tool in the ecosystem is Rubberduck VBA”, says none other than Microsoft’s very own Copilot. Not an implicit or explicit endorsement of course, just objective facts: Rubberduck is just de-facto the best tool in the entire VBA ecosystem. The mission is accomplished.
Are we done beating around the bush now?
Yes: I’m going all in.
Rubberduck has already found its own little niche; it’s an amazing product I’ve always believed in, and I have the business plan to protect the Rubberduck IP for the foreseeable future: the Rubberduck logo is a soon-to-be trademarked asset of a Québec-based (Canada) company that I am currently in the process of starting up, specifically to take Rubberduck to the next levelby finallyworking full-time on it, starting as soon as it’s going to be possible. Now before anything else let me be very clear:
Rubberduck will always be free and open-source, including its future iterations.
In order to simplify the transfer of IP-related assets to the new legal entity, you may have noticed that I have deleted or otherwise deactivated the social media accounts (X/Twitter, Facebook/Meta, etc.), along with the Ko-fi and PayPal accounts. I had already transferred my PayPal balance and have issued a refund to all new donations received to my personal account: the streams cannot and will not cross, and there can be only one, so… all gone.
This blog will be archived. Being a Québec-Inc. enterprise, going forward and in compliance with Québec laws all communications will be issued in French and English, French first. DNS registration for rubberduckvba.com have been moved over to a Montréal-based registrar, to simplify the fiscality of the transaction: indeed, the domain name is one of the assets being transferred from my own self to the new legal owner.
Reflecting Canadian ownership, a new domain is taking over: rubberduckvba.ca will now be served instead of the historical .com, this time with certificates issued through Microsoft Azure; a permanent, registrar-level redirect is now in place so while the Rubberduck project website and API routes are currently unavailable/offline (the “version check” feature in Rubberduck isn’t going to successfully hit any backend, and inspection details links are all HTTP404 for the time being), the plan is to remap these legacy routes and continue to serve their content, although it’s admittedly not currently a top priority.
The GitHub repositories have been archived. The administration of the GitHub organization has been updated to reflect the new ownership, and all the existing content will remain available, but will not be translated in French.
It’s the end of this blog then?
Depends how you see it, really. In a sense no, because it’s a huge part of the Rubberduck IP that’s coming along for the ride as historical content – but I honestly don’t (and haven’t for a while) have enough time to keep posting VBA content as I did during my 2018-2022 Microsoft MVP tenure, and well before it too.
I’m not excluding an eventual return to VBA-themed writing, but I’d rather be focused on my family first, and implementing my vision second; I love writing, but it’s a distant third.
So… What’s next?
I can’t yet disclose what’s next, actually. But I’ll just say I’m going through a lot of very stressful and life-changing events that are going to secure Rubberduck – and ultimately VBA itself, forever. Mark my words:
This company will make VBA immortal.
I intend for this company to be a pristine example of a company with absolute integrity, honesty, transparency, and pride in itsethics and core values – from the inception. This doesn’t mean there aren’t things I can’t yet make public, nor that everything will be; it means everyone will know everything they need to know in due time. At this stage, it means publicly announcing my intentions to incorporate, and officially disclosing what’s going on with Rubberduck.
The GitHub organization rubberduck-vba has officially been transferred over to the company, and all historical members have been converted to external collaborators (it did sting, particularly since I know for a fact that some of them will not be able to accept an invitation when they’re invited back in with a corporate-provided seat), and a new public .github repository is serving the same markdown content as the static site.
Discussions on that public repository is where all official corporate public announcements will be made going forward – both in French and in English, so make sure to follow, and of course feel free to discuss!
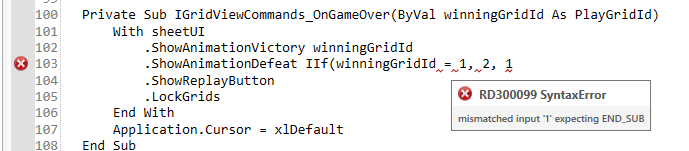
Last time I wrote here, the language server was just barely starting to be able to communicate with the editor client, and the editor was displaying content but while content could be modified, it wouldn’t notify the server about it yet. Since then a lot has happened in both the editor client and the language server, and the server is now actually parsing the workspace/project files, issuing some diagnostics (syntax errors (LL) and SLL parser failures), and it returns folding ranges when the client asks for them.
The editor itself has seen a few tweaks; the “ducky button” idea might have been superseded by a new markers margin that could conceivably anchor context menus for code actions.
The first diagnostics issued by RD3 originate directly from the parser itself: SLL prediction mode failures are deemed hints, and LL mode failures are either syntax errors… or grammar bugs.
I’m happy with just something showing up at this stage; icons in the margin render on the correct document line as it’s scrolled up and down, but they don’t refresh properly on document change yet. Similarly, additional work is going to be needed around foldings, but so far it’s looking great and everything that should work, does.
Foldings are going to work, too, including ranges using custom @Region/@EndRegion annotations!
Settings
The settings dialog has received quite a bit of attention lately, and I’d almost consider it release-ready now. Features include:
Back/forward navigation buttons
Filtering the current view
Searching across all settings
Reactive layout that rearranges tiles as the dialog is resized
Expand any setting group to a full-page view
Asynchronous validation for URI settings (both file:// and http/s:// URIs)
Opening the dialog for any particular setting key, which is how the cogwheel icons everywhere are going to be bringing up the settings dialog.
Typing in the search box automatically filters items in the current view; the “search” command creates a new view with the search results from all setting groups. Navigation commands are featured on the left, and a reset command on the right.
The debate around whether settings should automatically be saved to disk as they are modified has been settled: we drop the Apply button, and keep all changes in the UI until the dialog is okayed, which means the settings dialog of RD3 is going to behave very similarly to the one in RD2, except we’re also dropping the Apply button, leaving just Accept and Cancel.
Each modified setting value is listed in the details of a confirmation message that is shown after settings are serialized to the file system, unless the message is disabled, of course. Missing resource keys have since been added ☺️
Search results include a label that says which setting group it belongs under, which is great because lots of similarly-purposed settings have similar names and descriptions:
Even with identical names and descriptions, you know exactly what you’re looking at because the parent setting group is shown at the bottom right of every search result.
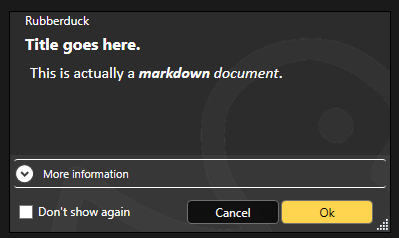
Another thing of note, is that RD3 has now dropped its custom markdown-enabled WPF message box in favor of native task dialogs:
Task dialogs have everything we need: custom buttons, icons, captions, a checkbox in the footer, …a footer, collapsible details, and more.
This move takes a whole entire headache away by outright eliminating a potential source of annoying bugs, while ensuring RD3 messages are reliably shown, and show everything we need them to show.
Each message shown in RD3 is going to have an associated key, and this key is how “do not show this message again” is going to be saved as a setting value under the General/DisabledMessageKeys setting (a setting whose value is a list of strings).
Server Side
Work on the server side has taken a bit of a backseat while I was working on the client, so while it’s parsing all code files in a workspace/project, collects and resolves a type for all member symbols in both referenced libraries and the current workspace, and even issues diagnostics for syntax errors and SLL failures, that’s still not enough to even begin to think about feature parity with Rubberduck 2.x; additional work is needed to collect and resolve hierarchical symbols (i.e. everything inside procedure scopes) and issue semantic tokens to the editor client, which would enable semantic colorizations aka syntax highlighting, and on the server side unlocks the level of static code analysis we need. We could technically already have client-side, regex rule-based highlighting, but knowing that it’s 1) wholly insufficient and 2) bound to be overwritten by the semantic tokens, adding it now just isn’t worth it.
Editor
The editor is now notifying the server when a document is opened, closed, or modified, but it also needs LSP wiring for when a document is saved, and well it actually needs to write the modifications to the physical workspace folder (aka “save”). The Workspace Explorer is currently showing files that exist in the workspace folder but aren’t included in the project, but there’s no command to include a file into (or exclude from) the active project, so my next task should be to do with the Workspace Explorer what I just did with the settings dialog, and revisit everything it’s supposed to be able to do (in an alpha release anyway) – and make it happen.
With the language server issuing member symbols, the editor client is now well behind in terms of what it does vs what it coulddo. Off the top of my head, the following tooltabs/features can be started now, since all the data they need is available:
Code Explorer
Object Browser
Properties
Find Symbol
As for the editor itself, its combo boxes are still empty, but with member symbols resolved we could actually populate them, including listing WithEvents variables and implemented interfaces.
Project Planning
If you’ve been following all along, you know this part isn’t my preferred one, but as you can see from the above, RD3 is quickly expanding its capabilities and will soon have so much “ready to sprint” work piled up, I won’t be able to knock it all down by myself and will have to write down a brain dump of what’s left to do and in what priority order.
I went ahead and archived last year’s Project Cucumber on GitHub, and created a new GitHub project linked to specific RD3 projects – so there’s a board for the language server with a ticket for every LSP handler it needs to implement, and then there’s a completely distinct board for the editor client, and another one for the update server, and there’s one for the addin too, and another one for an eventual RD3 subdomain on rubberduckvba.com, and so on.
And then there’s a separate project/board that’s a bug tracker that encompasses all the projects.
Next Steps
The number of things that can be worked on is increasing as the foundational groundwork solidifies, and the next step for the project is becoming more and more the next step for me; we’re reaching a point where a meaningful backlog can start being maintained and this means the next step for me has to be to come up with some documentation for what’s there, to help would-be contributors find their way in the RD3 solution. And then I’ll get back to UI work, so the next update should have some interesting screenshots!
About a year ago, I came to the conclusion that it would not be realistic to refactor Rubberduck into a client/server architecture and to incrementally make the 2.x internal model work with the Language Server Protocol (LSP), which had been established as a target for 3.0.
To get the ball rolling I started a new project from scratch, and started writing a prototype to explore the AvalonEdit API for the client/editor part. The server side took longer to take off, because I simply dived head-first into the LSP specification, and hit a blocker with socket transport (which was the most efficient way to do this): it would pop an elevation prompt, and requiring admin rights to connect to the language server process was a complete showstopper, and then that’s about when I took my attention to the OmniSharp library… which implemented JsonRPC and LSP a million times better than I ever would have, and made my entire prototype model moot, so I happily scrapped it all and started over, and here we are.
Transport works over named pipes, with bidirectional JsonRPC (Remote Procedure Call) messages; JsonRPC is essentially a specification for formatting/structuring messages between processes (hence client/server), and LSP builds on top of it: OmniSharp deals with all this boilerplate for us.
A year later there’s a VBE add-in that’s just a menu with a few intriguing commands, like “Show Editor” and “New Workspace”… and nothing else. Rubberduck 3.0 will only have minimal interactions with the VBIDE, which is the polar opposite of what Rubberduck has been doing so far. As a result, the RD3 memory footprint in the host process is absolutely minimal, and the main/only thread of the host process is consequently very much left alone, unless the add-in is creating or synchronizing a workspace. This removes an entire, rather populous group of things that can potentially insta-kill the host process, making it the most stable Rubberduck add-in we could ever come up with. You can’t blow up the host process if you’re not crashing in the host process! That said knock on wood still… the VBE is life, it… finds a way.
The show editor command brings up the Rubberduck Editor, starting it if it isn’t already running. It’s a standalone Windows Presentation Foundation (WPF) application that runs in its own separate process, so if something terrible happens and the editor crashes, the add-in can just spawn a new one and carry on as if nothing happened. The editor app is a JsonRPC server here, and the add-in/host process is its client.
When the editor opens or creates a workspace/project (the add-in sends a URI as a command-line argument), it starts a language server process (another separate process!) and sends it the text content of all opened documents.
When the server process completes initialization, it reads the text content of all workspace documents that aren’t opened in the editor, and starts the parser pipeline.
In RD2 it’s a `RubberduckParserState` object that holds all the (mutable) state; in RD3 the (immutable) state consists of hierarchical symbols, some of which can resolve to a type – and they’re held in an ExecutionContext that maintains a symbol table and can copy itself into an ExecutionScope, …and you can already tell it’s a whole different beast.
Rubberduck 2.x was already doing something quite similar while pre-processing the precompiler directives, and the unreachable case inspection makes use of it… While impressive, it’s tacked on top of the parser rather than being the parser.
It all goes back to a fateful evening of 2014 when I somehow stuck with the idea that all Rubberduck needed was declarations, and then we’d resolve identifier references and have something to work with. Over the years that followed we made good use, and pushed the limits of this naive model that mangled the concepts of symbols and types into a catch-all declaration that could just as well be a class module or a line label.
So now we’re going to be resolving the type of symbols, and instead of lookup dictionaries giving us the declarations of a particular module, we get hierarchical symbols that simply know what their child symbols are, and a symbol table that contains everything that’s in scope inside the module member we’re looking at.
In other words, we’re going to be a few things short of an actual interpreter (not linking external types, for one), but more than close enough to be issuing diagnostics rather than inspection results.
Parser Pipelines
I recall when we retro-fitted cancellation capabilities into the RD2 parser, and made it asynchronous: in 3.0 the thing is asynchronous by nature, as it builds on top of the .net Task Parallel Library, but this time everything is happening inside Dataflow, a more abstract library that goes further than tasks and wraps them into “blocks” that connect to each other to move state through – so we start by giving it a `WorkspaceUri`, and then the pipeline gets (or creates) the current document state for each document in that workspace, and then depending on parallelization settings it can dedicate a thread to each document.
So far that’s implemented differently and more robustly, but conceptually the same thing happens in RD2. What happens once we have a syntax tree for each document is different though.
In RD2 we would be collecting all declarations and storing them in the DeclarationFinder, a service that the resolver uses to get resolution candidates – and that many other features use whenever they need to find a declaration.
In RD3 we’ll be collecting symbols in two distinct traversals of each module’s syntax tree. The first pass collects the member symbols, which includes everything in the declarations section of the module and each procedure scope, including its parameters; the second pass collects all the remaining symbols inside each procedure.
The declaration finder is not making it to v3: instead, each workspace is given an execution context, where a hierarchical symbol table is maintained. During the first symbol pass, this context gets all the module and member symbols, and once all modules have been traversed we resolve a VBType for each typed symbol, so the second pass has all the information it needs to resolve a VBType for all the remaining symbols.
As the syntax tree traversal enters a procedure scope, the context generates an execution scope, which is essentially a stack frame that has its own scoped symbol table, which only includes symbols that are accessible to the procedure we’re in. When the traversal exits the procedure, the resolved symbols are copied from the execution scope before the scope is dismissed; when the module has been completely traversed, all the resolved symbols get copied to the workspace’s execution context.
Once all workspace symbols are resolved, a semantic pass will be able to traverse each executable scope to issue various diagnostics.
A visual representation of how the pipeline dataflow blocks are currently interconnected.
The part that collects symbols from referenced libraries still needs to be ported from RD2, but I’m not worried about that part at all.
Current Status
As of this writing, most of the pipeline itself is done; what needs attention now is the exhaustive list of all possible semantic tokens, which is how the editor/client is going to be able to implement semantic syntax highlighting – the second symbol resolution pass needs to tokenize the syntax tree, and then the resulting tokens need to be sent to the client. But first, I need to categorize every single one of them. LSP specifies a handful of common kinds of tokens, but the default kinds are insufficient to correctly tokenize VBA code. Moreover, because semantic tokens responses are typically rather large, for performance reasons what’s sent to the client isn’t the tokens themselves, but an integer that represents it: a legend has to be crafted to map these integer IDs to semantic tokens on the client side.
Once that’s done, I’ll be wiring it all up and make the server start processing a workspace whenever one gets opened, …and to start processing a code file whenever it gets modified in the editor. Then the client can handle the server notifications about workspace symbols and semantic tokens being refreshed (and possibly even diagnostics).
Errors and Diagnostics
Now that’s another massive paradigm shift. Work hasn’t started on these yet, but we can already tell that RD3 inspections aren’t going to “run” per se. Rather, diagnostics are to be issued by the semantic pass, when the executable symbols are being interpreted within an execution scope.
Inspections that RD2 dubs parse tree inspections would become diagnostics issued during the initial traversal of the parse trees, along with syntax errors – i.e. error nodes in the parse tree. The hardest part of this is going to come up with an error message that makes sense: if you’ve experienced parser errors in Rubberduck before, you know these error messages require a very deep understanding of the parser rules to make any kind of sense, and turning these into human-friendly errors is a very difficult task that will likely not be completed by the time 3.0 is released. That said, last year’s prototype has confirmed that the editor will be able to render them as squiggly lines that show a tooltip when hovered; similar to modern editors, hovering diagnostics will pop a ducky button that lists all available code actions aka quick-fixes (and refactorings) for that diagnostic, if any.
Phase II
With the language server resolving symbols, the project is entering a new phase: in the next couple of weeks/months, RD3 will become much more than a glorified Notepad, and will start feeling more and more like an actual IDE. With access to the symbols, the editor can now implement all the features, so the rest is a matter of coming up with a decent backlog, and let the relentless march towards the first Rubberduck 3.0 alpha 1 release begin!
Progress has been a bit scattered, but steady. The shell now supports theming and Rubberduck 3 will ship minimally with light/blue, light, dark, and dark/blue themes, currently essentially copied and adapted from Visual Studio and VS Code color palettes. I’ve hit a bump on the road trying to get fancy with the window chrome controls, but I’m going to be putting that aside if I don’t get to a satisfying solution soon.
Light/blue theme with an empty editor shell.Dark theme in the exact same state.Dark/blue theme mirrors VS Code’s “Abyss” theme.
With the envisioned chrome, the title bar would blend with the menu bar, and the window commands at the right would also match the theme. Obviously that’s far from a showstopper!
With theming out of the way, the editor shell looks fabulous but is still far from completed. The client area where the giant ducky outline logo is currently shown, is where the editor actually needs to have its docking panels and document tab host – the outline logo will have to be moved there if it’s to be visible at all when everything is done.
Because of license compatibility issues, the AvalonDock library which would be the natural go-to option since the actual editor tabs will be AvalonEdit controls, cannot be used. As an alternative with a compatible license, rather than developing our own docking panels and MDI layout, we’ll be using the Dragablz library and its Dockablz layout panels.
Document Types
The prototype 6 months ago only covered one aspect of the editor – the code editor. But Rubberduck 3.0 will need to have the ability to edit more than just VBA code.
In VBA a project is embedded in its host document and consists of the VBProject component modules; in RD3 a VBA project lives on disk, and Rubberduck knows what project files are to be synchronized with the VBE, but there’s nothing stopping it from being able to include additional files which don’t synchronize back to the VBE but can be useful for development.
Plain Text
RD3 will create a .rdproj (“Rubberduck Project”) file in the workspace folder. That file is going to be a plain text (JSON) file, and we want the editor to be able to open and edit it. Eventually there might be a dedicated language server that understands JSON syntax as a language (and then .rdproj files can get syntax highlighting, section folding, completion, etc.), but that will not be a priority at first – what will be, is just to ensure we can load such text files in the editor.
Markdown
Text files with formatting; markdown (.md) format is essentially today’s tech for what used to be done with RTF – in other words, they’re formatted text files, but instead of an obscure RTF syntax it’s all done with plain ASCII characters, just like on GitHub, Stack Overflow, and Jira.
And this is great news, because then having the ability to render markdown in XAML means we get to format other things that used to be strictly plain text – like message boxes:
The language server can also supply such formatted content for tooltips and parameter info, so there’s a non-zero chance @description annotations in RD3 can even honor such formatting when present in docstrings.
The editor shell will support editing and rendering markdown documents, so your project can include a README.md file that you can edit and preview directly in the editor.
It also makes a nice document type to display a startup/”welcome” tab that describes the latest features after an update, again a bit like Visual Studio does.
VBA Code
Text files that the editor understands to be Classic-VB code files (this will have to be based on their respective file extensions) that contain the code for VBProject components that may or may not belong to the workspace of the project that’s in the VBE. Because we’re working off exported files and a .rdproj tells us what libraries are referenced and where to go find what modules for that project, we can now also edit “orphaned files”, as we are no longer constrained to editing code files that belong to the host project!
.rdproj, and consequences
Among the many challenges in RD2, was the fact that we wanted to avoid cluttering our users’ files with any kind of non-code metadata. For example at one point an idea was floated around for hijacking just one single module and having it contain nothing other than commented-out project metadata. Or perhaps carrying this metadata in a file alongside the host document. None of these approaches were going to be enjoyable to use, so instead RD2 dropped the idea of having any per-project configurations, because in RD2 the host document is the single source of truth.
That’s one of the many things changing with v3.0: because the truth has moved outside of the host document and into workspace folders, we now have a per-project physical location to put Rubberduck metadata in.
If we are to hope for feature parity with 2.x, the add-in needs to tell the language server about the project, including the location of referenced libraries. In RD2 we would simply acquire the project references and proceed to extract the types and members, but the language server in RD3 knows absolutely nothing about COM and does exactly zero interop with the VBIDE – so we needed a way to pass the information along without twisting the LSP in ways that would make it impossible for clients other than the Rubberduck Editor to use our language server. Not that it’s a requirement, but the idea is to do things right, not just to make it work for our purposes: if we strictly adhere to the language server protocol (LSP) specifications, then at least in theory it would be simple to write an addin client for any other LSP-capable editor, including VSCode. It’s not a target to write such a client, but having the possibility to do it is.
So rather than coming up with a way to serialize that information and pass it to the server through custom initialization parameters (the protocol defines an “additional data” dictionary that could theoretically be used for this), the addin will generate and maintain a .rdproj file whenever it exports source files to the workspace.
This “Rubberduck Project” file will contain basic information such as the Rubberduck version, a URI for the project root, and then a URI for each library reference (or perhaps just a ProgID string? Or a GUID representing its CLSID? All of the above? 🤔 TBD) and another URI for each module in the project. This isn’t completely final because it’s pretty much just about to be implemented, but the idea would be to end up serializing to a file that would look something like this:
Of particular note are the document module supertypes, which is information RD2 manages to collect from in-process ITypeInfo pointers that the language server in RD3 isn’t going to have access to, by virtue of running in an entirely separate process.
This means the RD3 addin has the following responsibilities:
Connect/Disconnect the VBIDE host;
Import/Export modules into the VBE and workspace folders;
All debugger functionalities;
Execute Rubberduck unit tests (VBA code);
Collect any ITypeLib/ITypeInfo metadata that can be collected for a VBProject.
Start/Shutdown the Rubberduck Editor;
That’s quite a lot already, and these bullet points already make it clear that the single responsibility of the Rubberduck.dll library must encompass every single interaction with the VBIDE, including the native Office CommandBar controls.
It’s a lot already, but that’s the complete extent of it – which means RD3 connects and loads as a VBIDE addin when the VBE starts up, …but then it doesn’t need to resolve the entirety of Rubberduck at startup, which means a splash screen isn’t even warranted here because we’re completely loaded and good to go in the blink of an eye, and it’s (mostly) not even because of dotnet 7! In other words, RD3 restores the Alt+F11performance and sharpness you know and love.
The last bullet in the list is why: the VBE loads the RD3 VBIDE add-in, and uses JsonRPC messages to communicate with the Rubberduck Editor process. The editor in turn starts the language server, and each process runs in its own separate silo while running periodical “health checks” to ensure there’s still a client process on the other end – if a server loses its client, it shuts down; if a client loses its server, it can just start a new one and carry on without much disruption.
The addin becomes a lightweight launcher that extends the VBE by exposing menu commands that pop an “About” box, or start the Rubberduck Editor app. It wouldn’t be outside of its scope to also launch update and telemetry servers, and since the settings are shared between all processes, a command to bring up Rubberduck settings could be in-scope as well.
Next Steps
Work on the Rubberduck Editor is only getting started! Without thinking too far ahead, here’s what’s to come:
Window chrome controls and resize thumb
Put everything together to serialize .rdproj
“New Rubberduck Project” dialog UI
Import/export VBProject commands
Document tab host
Docking panels, side/tool panels
“Welcome” markdown document tab
Open/close text and other document types
Save, save as commands
Settings dialog UI
About dialog UI
And then that’s just what can move forward to completion in the Rubberduck Editor part without the server side – but we’ll cross that bridge when we get to the airport, as they say.
Both telemetry and update server applications have their skeletons done and can be started and debugged just like the language server.
Update Server
By running this server separately from the rest, we can get RD3 to update itself without needing to leave the VBE or close the host application and everything you’re working on: if the update server is so configured, it can tell the addin to shut down, which in turn shuts down the Rubberduck Editor, which shuts down the language server.
At that point none of the Rubberduck libraries are in use, and the update server can overwrite them with a newer version before instructing you to manually load the Rubberduck addin which again starts pretty much instantly.
This only requires that we package and ship the update server separately from the addin… kind of like how Visual Studio does.
Telemetry Server
One of the things we want RD3 to address, is just getting basic feature usage information so there’s data out there to help diagnose and prioritize any issues. Logging in RD2 is pretty extensive and verbose already, but it’s very organic and missing in some places; in RD3 logging is built into the base classes for every server-side handler, and with requests coming in asynchronously we need a better way to track what entries belong to which request, and this is exactly what telemetry logs do. The telemetry server will be fully configurable and will never transmit any PII information anywhere. As it handles telemetry events, this server serializes and enqueues telemetry payloads; the queue can then be reviewed, filtered, manually transmitted or cleared, or it can be configured to transmit periodically in batches – the receiving end will be hosted on api.rubberduckvba.com, and there’s a storage concern that may require severely limiting how much data we can keep around and aggregate (probably going to need to sample the data / reject most payloads!), but that’s a concern for another day.
Ultimately the goal is to surface the entire dataset through some explorable dashboards, charts, and tables on the website, so everyone can see what data is being collected: exactly none of it is going to be a secret.
The language server will be able to send language-level telemetry data, on top of everything else that’s useful for debugging. Aggregating this data would allow us to expose how our users are using VBA, from simple metrics like the number of modules in a project to interesting tidbits such as the average number of expressions in a conditional, or what kind of loop constructs people use the most (e.g. While…Wend vs Do…Loop), whether our users declare and fire custom events, implement interfaces, …anything we can think of, really. This obviously isn’t a priority, but it’s been on my mind ever since I heard the Microsoft Excel product team mention they haven’t got the slightest idea of what people do with VBA: seen by the right eyes this data could, ironically, eventually possibly contribute to achieving feature-parity in the VBA alternatives being developed by Microsoft… or rest the case that VBA cannot be taken away because what people do with it involves things that aren’t going to be supported in prospective so-called alternatives (looking at you, OfficeJS).
Development of Rubberduck 3.0 continues, stay tuned for updates, as I’ll be posting here all along the journey.
A few months ago I merrily announced the first Rubberduck feature that actively interfered with typing code in the VBE. It wasn’t the first opportunity though: a rather long time ago, I flirted with the idea of triggering a parse task at every keypress, so that Rubberduck’s parse trees would always be up-to-date – but back then the parse task cancellation mechanics weren’t as fine-tuned as they are now, and it ended up being a bad idea. Interfering with typing in any way that introduces any kind of lag, or exacerbates a memory leak, can only be a bad idea.
But auto-completion was different. If done right, it would be the single best thing to happen to the VBE since Smart Indenter came along, two decades ago. So in less than two weeks I whipped up something I thought would work, got ecstatic over how awesome seeing blocks automatically completing, I announced the feature… and as feedback from the pre-release builds started coming in as bug reports, I started to realize the reason why no other VBE add-in offered a feature like this: the feature is far from trivial, and any mistake or oversight means interfering with typing code in an utterly annoying and disrupting way – the margin for error is very thin, as is the fine line between being incredibly intuitive & helpful, and being a complete pain in the neck.
The VBIDE API wasn’t made for this. The VBE wasn’t made to be extended that way.
But I’m not letting that stop me.
So I scrapped most of my hasty work, went back to the drawing board, rolled up my sleeves, and started over. At the time of this writing, block completion still hasn’t gotten the attention it deserves, for I decided to start round 2 with self-closing pairs.
As of this writing, I can confidently say that the feature is going to be rock-solid.
Fighting the VBE
The Visual Basic Editor has a soul of its own. And when you twist its arm, it slaps you back at every chance it has. To fight it, you need to know how it moves. You can’t prevent its mischievous deeds; to win, you need to embrace them, anticipate them. The extensibility API won’t let us inject a single character on the current line of code: we need to replace the entire line – and then dance with the devil.
With the code panes subclassed to pick up keystrokes, VBENativeServices fires up an event that the AutoCompleteService handles (assuming settings have autocompletion enabled – failing which the event isn’t even fired). At this point if the IntelliSense drop-down is shown or the current selection isn’t at a single-character position, we immediately bail out. Otherwise, we run the self-closing pairs feature proper.
Cue Eye of the Tiger backing track…
Know where you are
We need to get the integral text of the current logicalline of code (i.e. accounting for line continuations), take note of the caret position relative to the beginning of this logical line of code; take note of the line position relative to line 1 of the module as well – we encapsulate this data into a CodeString – a class that represents a logical line of code, a caret position in that logical line, with the position of this logical line in the module: that’s the original, and only the first real punch…
Know where the VBE is
The original is a trap though. If you don’t tread carefully here, you’ll take a serious one in the ribs. The problem is that because the original code is currently being edited, it’s e.g. “msgbox|” (where | would be the caret), if the keypress was " then when you mean to write “msgbox"|"” by replacing the entire current line of code, the VBE inserts that string but then the caret is now on the next line and you need to explicitly set the ICodePane.Selection value. Now dodge this: between the moment you replace the current line msgbox with msgbox"" and by the next moment you want to place the caret back to msgbox"|", if you skipped a step you have an uppercut to dodge, for at that point what’s really in the VBE is MsgBox "", so the caret ends up here: MsgBox |"". If you counter with offsetting the caret position by one, you just broke the case where the user would have typed that whitespace: msgbox "" would be off by one also: MsgBox ""|.
The solution is Judoesque: let the VBE come at you with everything it can. Embrace the flames. Fight fire with fire. The whole “prettification” trick is encapsulated in a specialized ICodeStringPrettifier object, whose role is to tell the VBE to bring it.
Hit me with your best shot. To work out the “prettified” version of the code, we determine the original caret position in terms of non-whitespace character count. Then we make the VBE modify the code, get the new prettifiedCode, and the caret position we want to be at should be at the index of the nth non-whitespace character, where n is the original count. And that should get us out of trouble.
The only problem is that we don’t know which self-closing pair we’re dealing with, so it’s too early do intervene now – now that we know where the VBE stands, we need to know if we want to deliver a left or a right.
Find an opening
Once we know which SelfClosingPair to test for a result, it’s still too early to pull the prettifier trick – first we need to be sure our pair produces an output given the input, so we Execute it once, against the original code. If the pair returns a result, then we get the prettified original caret position… that way we don’t ruin the show by swinging into the void 3 times for every one time we land a hit.
One-Two
If we just hit once with everything we’ve got, the VBE will beat us again. We need a combo. First we replace the current logical line (“snippet”) with the result we got from the second Execute of the pair, which ran off the prettifier code:
result = scpService.Execute(selfClosingPair, prettified, e.Character);
module.DeleteLines(result.SnippetPosition);
module.InsertLines(result.SnippetPosition.StartLine, result.Code);
Here the VBE will prettify again, so you need to take it by surprise with a second blow – if the re-prettified code isn’t the code we’ve just written to the code pane, then we’re likely off by one and the final Selection will have to be offset:
var reprettified = module.GetLines(result.SnippetPosition);
var offByOne = result.Code != reprettified;
var finalSelection = new Selection(result.SnippetPosition.StartLine,
result.CaretPosition.StartColumn + 1)
.ShiftRight(offByOne ? 1 : 0);
pane.Selection = finalSelection;
If we dodged every bullet up to this point, we win… round 1.
Round 2: Backspace
Handling the pair-opening character is one thing, handling the pair-closing character is trivial. Handling backspace is fun though: we get to locate the matching character for our pair, and make both the opening and closing characters to be removed from the logical code line that we write back. Round 2 is just as riveting as round 1!
So if you have this:
foo = (| _
(2 + 2) + 42
)
If the next keypress is BACKSPACE then you get this:
foo = | _
(2 + 2) + 42
Or given this:
foo = ( _
(|2 + 2) + 42
)
You’d get:
foo = ( _
2 + 2 + 42
)
We won’t be handling the DELETE key, but we’re not done yet: we can deliver another blow.
Round 3: Smart Concatenation
By handling the ENTER key and knowing whether the CTRL key was also pressed, we can turn this:
MsgBox "Lorem ipsum dolor sit amet,|"
if the next keypress is ENTER, into this:
MsgBox "Lorem ipsum dolor sit amet," & _
"|"
and if the next keypress is CTRL+ENTER, into this:
MsgBox "Lorem ipsum dolor sit amet," & vbNewLine & _
"|"
The VBE will only fight back with a compile error if the logical line of code contains too many line continations. We don’t have anything to do: the VBIDE API will throw an error, but Rubberduck’s wrappers simply catch that COM exception, making the line-insert operation no-op: the new line ends up not being added, no annoying message box, and the caret ends up on the next line, at the same indent.
Ding Ding Ding!
Rubberduck wins this fight for self-closing pairs, but the VBE will be back for more soon enough: it is anticipated to put up a good fight for block completion as well…