
As I wrote last July, I’ve started to get more time for myself lately, and that means I get to tackle a number of long-standing projects that have been on the backburner for way too long. One of them is the rewrite of the project’s website, which has been “under construction” ever since it was published as an ASP.NET MVC website, a few years ago already.
If you missed it, I tweeted a sneak-peek link last week:

Why a rewrite?
For the longest time, I wouldn’t have considered myself a web developer. I have well over a decade of experience in C# desktop development, but the web stuff essentially scared me to death. The version of the website that’s currently live was pretty much my first time doing anything like it. The site itself wouldn’t write to the database; it was another application that pulled the tag metadata, downloaded the xml-doc assets, parsed the documentation and examples, and wrote them to the database.
One of the biggest issues with the current model, is that the database is made to contain HTML that is needlessly difficult to modify:
Unreachable code is certainly unintended, and is probably either redundant, or a bug.
<div><h5>Quick-Fixes</h5>
<p>The following quick-fixes are available for this inspection:</p>
<ul style="margin-left: 8px; list-style: none;">
<li>
<span class="icon icon-ignoreonce"></span>
<a href="https://rubberduckvba.com/QuickFixes/Details/IgnoreOnce">IgnoreOnce</a>
: Adds an '@Ignore annotation to ignore a specific inspection result. Applicable to all inspections whose results can be annotated in a module.</li>
<li>
<span class="icon icon-tick"></span>
<a href="https://rubberduckvba.com/QuickFixes/Details/IgnoreInModule">IgnoreInModule</a>
: Adds an '@IgnoreModule annotation to ignore a inspection results for a specific inspection inside a whole module. Applicable to all inspections whose results can be annotated in a module.
</li>
</ul>
</div>
Having this HTML markup, CSS classes, and inline styles as part of the data meant the data was being responsible for its own layout and appearance on the site. With the new JSON objects serialized into this Properties column, I could easily keep everything strongly typed and come up with separate view models for inspections, quick-fixes, and annotations, that each did their own thing and let the website in charge of the layout and appearance of everything.
Separation of Concerns
The solution architecture could be roughly depicted like this – I suppose I meant the arrows to represents “depends on” but note that this doesn’t necessarily mean a direct project reference: the Client/API relationship is through HTTPS, and no project in the solution references the Rubberduck.Database SQL Server database project, but ContentServices connects to a rubberduckdb database that you can deploy locally using that database project:

You could draw a thick red line between Rubberduck.Client and Rubberduck.API (actually that’s Rubberduck.WebApi now), and it would perhaps better illustrate the actual wall between the website and the data: the website project doesn’t need a connection string, only a base URL for the API!
Authentication is assured with GitHub’s API using OAuth2: if you authorize the rubberduck-vba OAuth application to your profile, the HttpContext.User is cast as a ClaimsPrincipal and claims the GitHub login as a name, and a rubberduck-org role claim is added when organization membership is validated; an additional rubberduck-admin role claim is added if the user is also a member of the WebAdmin org team.
The website packages the HttpContext.User into a Json Web Token (JWT), an encrypted string that encapsulates the claims; this token is passed as a bearer token in authenticated API requests. The API accepts an Authorize header with either such a bearer token, or a valid GitHub personal access token (PAT).
The API receives a request, and given an Authorization header, either decrypts the JWT or queries GitHub to validate the provided access token and attach the appropriate role claims, before any controller action is invoked.
Another authentication filter performs a similar task to authorize an incoming webhook payload: the rubberduck-webhook role is set and tag metadata and xml-doc content can get updated automatically whenever a new tag/release gets created.
Performance
This new website performs much, much better than the current one. It sends asynchronous (ajax) requests to the MVC controller to render partial views, fetching only enough information to paginate the data and present a decent preview. Since most pages are presenting markdown content, an asynchronous request is also sent to format the markdown and, if applicable, apply syntax highlighting to code blocks. At this stage static content isn’t being cached yet, and screenshots should be loaded dynamically – still, performance is quite decent:

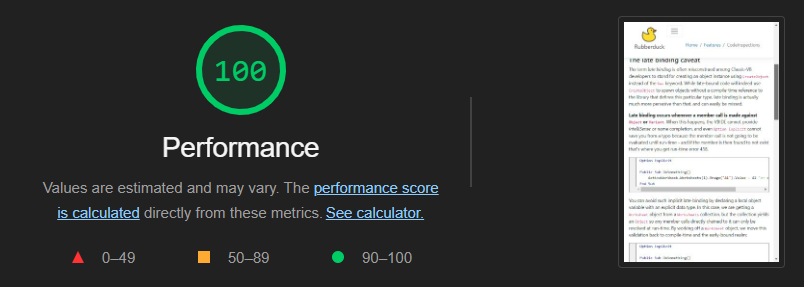
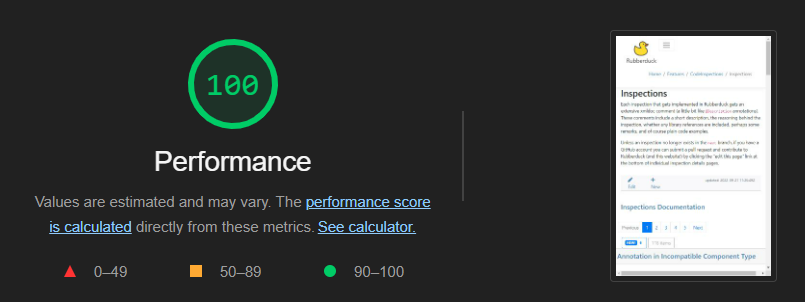
Home page scores 94, but then both Code Inspections and Inspections pages (two pages with extensive content, lots of markdown, code blocks, etc.) score a full 100 with Google Lighthouse, so things are looking very good performance-wise.
Another detail: the code examples no longer trigger a page load when you select a tab, so everything just feels much smoother now. Note, as of this writing the example records have been wiped from the database while I work on fixing a problem with the xml-doc processing, so annotations, inspections, and quick-fixes aren’t showing any examples on the test site for now.
Online Indenter
This feature once worked, but then my inexperienced past self, went and broke it in an attempt to make it asynchronous. Well, it’s back online and running Rubberduck.SmartIndenter.dll version 2.5.2:
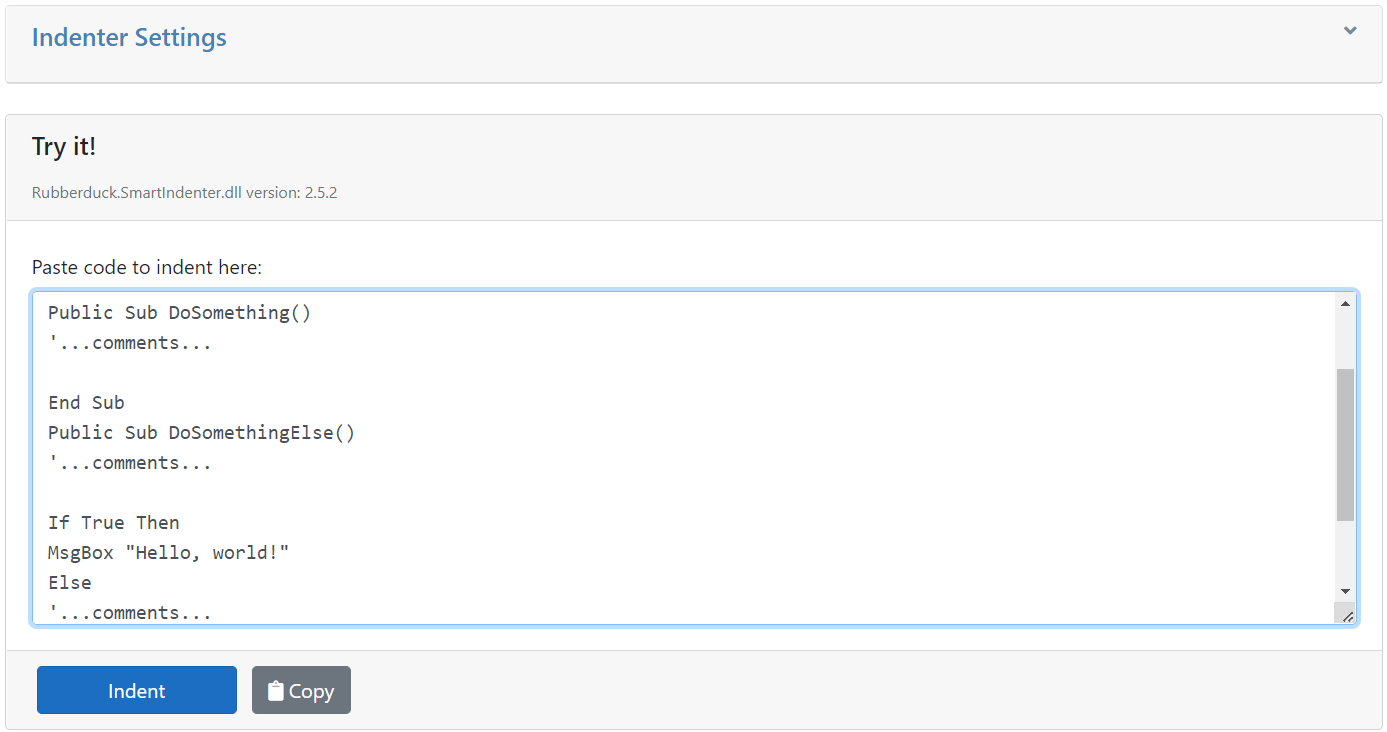

The code can be indented as per the default indenter settings (which are also used for indenting all syntax-highlighted code blocks on the site), or if you expand the Indenter Settings panel you can tweak every knob Rubberduck’s Smart Indenter port has to offer.

It wouldn’t be too hard to include a “download these settings” button here, to serialize the settings into a .xml file that Rubberduck can then import to update indenter settings.
Content Administration
Users with the appropriate claims will be able to see additional buttons and commands on the site:

Content administration features still need a little bit of work, but they are already being used to document how to use each and every single feature in Rubberduck – once this documentation is completed, the site will be a huge user manual, and ready for launch!
What’s Next?
Once everything works as it should (getting very close now!) and all that’s left to do is to take screenshots and generate more content, I’ll shift my focus to the Rubberduck3 project, the ownership of which I’ve now transferred over to the rubberduck-vba organization – the repo remains private for now, but all Rubberduck contributors have access to it. Uploading the RubberduckWebsite solution as a public repository isn’t a priority at this point; I feel like dealing with the implications of having API secrets in a .config file would be a distraction that I don’t need right now. When the time comes, it’ll be properly setup with continuous integration and deployment, but there are other priorities for now.
Like this little guy…


very happy to see that Rubberduck 3 is being worked on!
LikeLiked by 1 person
Thanks for sharing, always interesting to read about your approach!
LikeLike